- 1.2 主要设计特点
1.2 主要设计特点
TIMIT 演示了语料库设计中的几个主要特点。首先,语料库包含语音和字形两个标注层。一般情况下,文字或语音语料库可能在多个不同的语言学层次标注,包括形态、句法和段落层次。此外,即使在给定的层次仍然有不同的标注策略,甚至标注者之间也会有分歧,因此我们要表示多个版本。TIMIT 的第二个特点是:它在多个维度的变化与方言地区和二元音覆盖范围之间取得平衡。人口学统计的加入带来了许多更独立的变量,这可能有助于解释数据中的变化,便于以后出于在建立语料库时没有想到的目的使用语料库,例如社会语言学。第三个特点是:将原始语言学事件作为录音来捕捉和作为标注来捕捉之间有明显的区分。两者一致表示文本语料库正确,原始文本通常有被认为是不可改变的作品的外部来源。那个作品的任何包含人的判断的转换——即使如分词一样简单——也是后来的修订版,因此以尽可能接近原始的形式保留源材料是十分重要的。
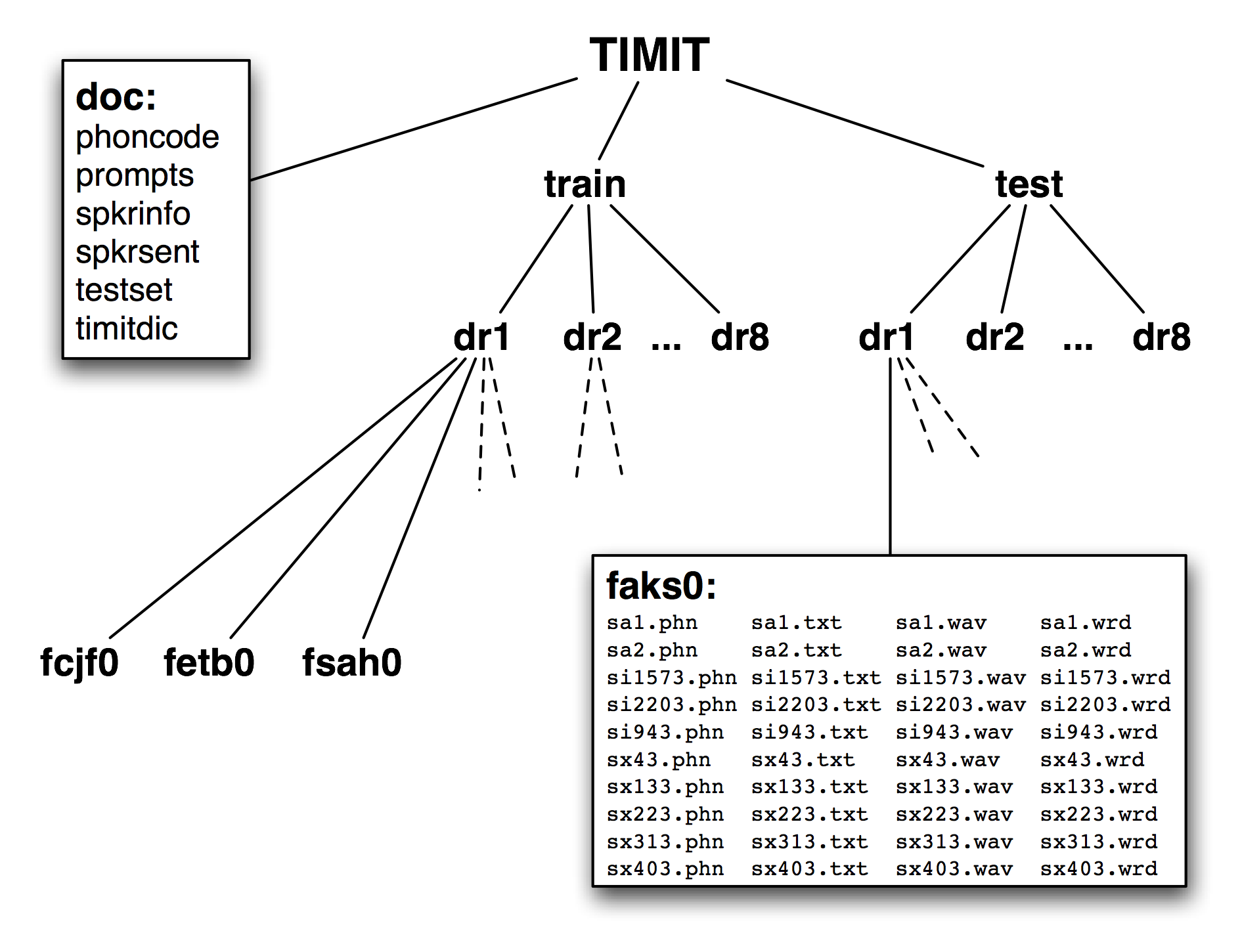
图 1.2:发布的 TIMIT 语料库的结构:CD-ROM 包含文档、顶层的训练和测试目录;训练和测试目录都有 8 子目录,每个方言区一个;这些目录又包含更多子目录,每个说话者一个;列出的目录是女性说话者aks0的目录的内容,显示 10 个wav文件配以一个录音文本文件、一个录音文本词对齐文件和一个音标文件。
TIMIT 的第四个特点是语料库的层次结构。每个句子 4 个文件,500 个说话者每人 10 个句子,有 20,000 个文件。这些被组织成一个树状结构,示意图如1.2所示。在顶层分成训练集和测试集,用于开发和评估统计模型。
最后,请注意虽然 TIMIT 是语音语料库,它的录音文本和相关数据只是文本,可以使用程序处理了,就像任何其他的文本语料库那样。因此,许多在这本书中所描述的计算方法都适用。此外,注意 TIMIT 语料库包含的所有数据类型分为词汇和文字两个基本类别,我们将在下面讨论。说话者人口学统计数据只不过是词汇数据类型的另一个实例。
当我们考虑到文字和记录结构是计算机科学中关注数据管理的两个子领域首要内容,即全文检索领域和数据库领域,这最后的观察就不太令人惊讶了。语言数据管理的一个显着特点是往往将这两种数据类型放在一起,可以利用这两个领域的成果和技术。
