- 5.1 底层的概率模型
5.1 底层的概率模型
理解朴素贝叶斯分类器的另一种方式是它为输入选择最有可能的标签,基于下面的假设:每个输入值是通过首先为那个输入值选择一个类标签,然后产生每个特征的方式产生的,每个特征与其他特征完全独立。当然,这种假设是不现实的,特征往往高度依赖彼此。我们将在本节结尾回过来讨论这个假设的一些后果。这简化的假设,称为朴素贝叶斯假设(或独立性假设),使得它更容易组合不同特征的贡献,因为我们不必担心它们相互影响。
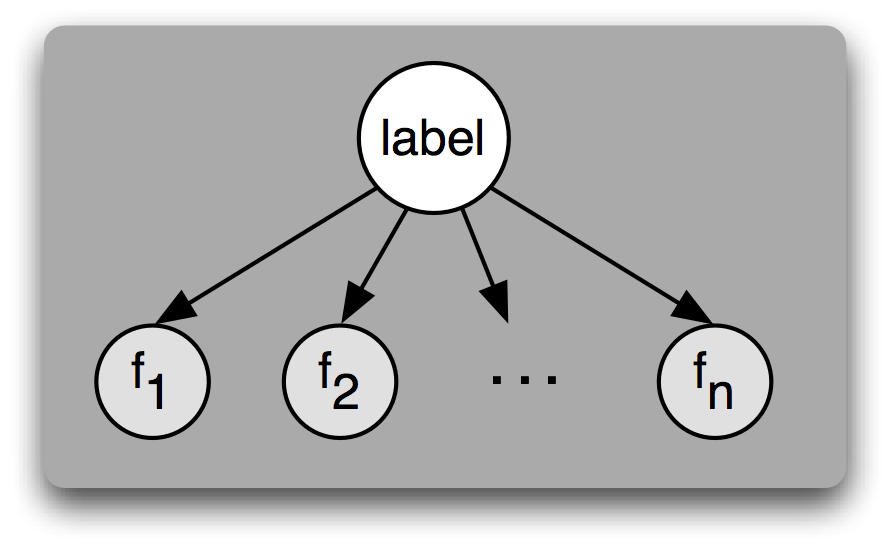
图 5.3:一个贝叶斯网络图演示朴素贝叶斯分类器假定的生成过程。要生成一个标记的输入,模型先为输入选择标签,然后基于该标签生成每个输入的特征。对给定标签,每个特征被认为是完全独立于所有其他特征的。
基于这个假设,我们可以计算表达式 P(label|features),给定一个特别的特征集一个输入具有特定标签的概率。要为一个新的输入选择标签,我们可以简单地选择使 P(l|features)最大的标签 l。
一开始,我们注意到 P(label|features)等于具有特定标签 和 特定特征集的输入的概率除以具有特定特征集的输入的概率:
>>> from nltk.corpus import senseval>>> instances = senseval.instances('hard.pos')>>> size = int(len(instances) * 0.1)>>> train_set, test_set = instances[size:], instances[:size]
使用这个数据集,建立一个分类器,预测一个给定的实例的正确的词意标签。关于使用 Senseval 2 语料库返回的实例对象的信息请参阅http://nltk.org/howto上的语料库 HOWTO。
☼ 使用本章讨论过的电影评论文档分类器,产生对分类器最有信息量的 30 个特征的列表。你能解释为什么这些特定特征具有信息量吗?你能在它们中找到什么惊人的发现吗?
☼ 选择一个本章所描述的分类任务,如名字性别检测、文档分类、词性标注或对话行为分类。使用相同的训练和测试数据,相同的特征提取器,建立该任务的三个分类器::决策树、朴素贝叶斯分类器和最大熵分类器。比较你所选任务上这三个分类器的准确性。你如何看待如果你使用了不同的特征提取器,你的结果可能会不同?
☼ 同义词 strong 和 powerful 的模式不同(尝试将它们与 chip 和 sales 结合)。哪些特征与这种区别有关?建立一个分类器,预测每个词何时该被使用。
◑ 对话行为分类器为每个帖子分配标签,不考虑帖子的上下文背景。然而,对话行为是高度依赖上下文的,一些对话行序列可能比别的更相近。例如,ynQuestion 对话行为更容易被一个
yanswer回答而不是以一个问候来回答。利用这一事实,建立一个连续的分类器,为对话行为加标签。一定要考虑哪些特征可能是有用的。参见1.7词性标记的连续分类器的代码,获得一些想法。◑ 词特征在处理文本分类中是非常有用的,因为在一个文档中出现的词对于其语义内容是什么具有强烈的指示作用。然而,很多词很少出现,一些在文档中的最有信息量的词可能永远不会出现在我们的训练数据中。一种解决方法是使用一个词典,它描述了词之间的不同。使用 WordNet 词典,加强本章介绍的电影评论文档分类器,使用概括一个文档中出现的词的特征,使之更容易匹配在训练数据中发现的词。
★ PP 附件语料库是描述介词短语附着决策的语料库。语料库中的每个实例被编码为
PPAttachment对象:
>>> from nltk.corpus import ppattach>>> ppattach.attachments('training')[PPAttachment(sent='0', verb='join', noun1='board',prep='as', noun2='director', attachment='V'),PPAttachment(sent='1', verb='is', noun1='chairman',prep='of', noun2='N.V.', attachment='N'),...]>>> inst = ppattach.attachments('training')[1]>>> (inst.noun1, inst.prep, inst.noun2)('chairman', 'of', 'N.V.')
选择
inst.attachment为N的唯一实例:>>> nattach = [inst for inst in ppattach.attachments('training')... if inst.attachment == 'N']
使用此子语料库,建立一个分类器,尝试预测哪些介词是用来连接一对给定的名词。例如,给定的名词对”team”和”researchers”,分类器应该预测出介词”of”。更多的使用 PP 附件语料库的信息,参阅
http://nltk.org/howto上的语料库 HOWTO。- ★ 假设你想自动生成一个场景的散文描述,每个实体已经有了一个唯一描述此实体的词,例如 the jar,只是想决定在有关的各项目中是否使用 in 或 on,例如 the book is in the cupboard 对比 the book is on the shelf。通过查找语料数据探讨这个问题;编写需要的程序。
| (13) | |
| a. | | in the car versus on the train |
| b. | | in town versus on campus |
| c. | | in the picture versus on the screen |
| d. | | in Macbeth versus on Letterman |
|
关于本文档…
针对 NLTK 3.0 作出更新。本章来自于 Natural Language Processing with Python,Steven Bird, Ewan Klein 和Edward Loper,Copyright © 2014 作者所有。本章依据 Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License [http://creativecommons.org/licenses/by-nc-nd/3.0/us/] 条款,与 自然语言工具包 [http://nltk.org/] 3.0 版一起发行。
本文档构建于星期三 2015 年 7 月 1 日 12:30:05 AEST
