- 3.1 频率分布
3.1 频率分布
我们如何能自动识别文本中最能体现文本的主题和风格的词汇?试想一下,要找到一本书中使用最频繁的 50 个词你会怎么做?一种方法是为每个词项设置一个计数器,如图3.1显示的那样。计数器可能需要几千行,这将是一个极其繁琐的过程——如此繁琐以至于我们宁愿把任务交给机器来做。
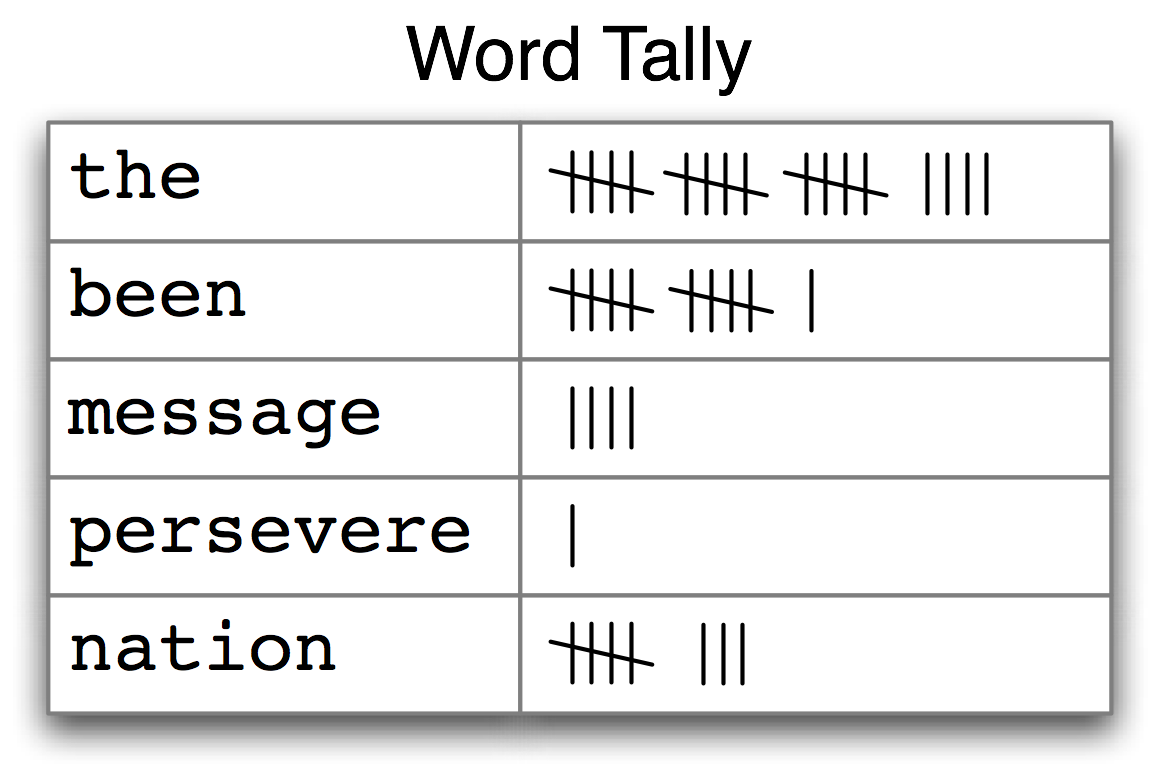
图 3.1:计数一个文本中出现的词(频率分布)
图3.1 中的表被称为频率分布,它告诉我们在文本中的每一个词项的频率。(一般情况下,它能计数任何观察得到的事件。)这是一个“分布”因为它告诉我们文本中单词词符的总数是如何分布在词项中的。因为我们经常需要在语言处理中使用频率分布,NLTK 中内置了它们。让我们使用FreqDist 寻找 《白鲸记》 中最常见的 50 个词:
>>> fdist1 = FreqDist(text1) ![[1]](/projects/nlp-py-2e-zh/Images/4b5cae275c53c53ccc8f2f779acada3e.jpg)>>> print(fdist1) ![[2]](/projects/nlp-py-2e-zh/Images/3a93e0258a010fdda935b4ee067411a5.jpg)<FreqDist with 19317 samples and 260819 outcomes>>>> fdist1.most_common(50) ![[3]](/projects/nlp-py-2e-zh/Images/334be383b5db7ffe3599cc03bc74bf9e.jpg)[(',', 18713), ('the', 13721), ('.', 6862), ('of', 6536), ('and', 6024),('a', 4569), ('to', 4542), (';', 4072), ('in', 3916), ('that', 2982),("'", 2684), ('-', 2552), ('his', 2459), ('it', 2209), ('I', 2124),('s', 1739), ('is', 1695), ('he', 1661), ('with', 1659), ('was', 1632),('as', 1620), ('"', 1478), ('all', 1462), ('for', 1414), ('this', 1280),('!', 1269), ('at', 1231), ('by', 1137), ('but', 1113), ('not', 1103),('--', 1070), ('him', 1058), ('from', 1052), ('be', 1030), ('on', 1005),('so', 918), ('whale', 906), ('one', 889), ('you', 841), ('had', 767),('have', 760), ('there', 715), ('But', 705), ('or', 697), ('were', 680),('now', 646), ('which', 640), ('?', 637), ('me', 627), ('like', 624)]>>> fdist1['whale']906>>>
第一次调用FreqDist时,传递文本的名称作为参数![[1]](/uploads/projects/1594/65793.jpg) 。我们可以看到已经被计算出来的 《白鲸记》 中的总的词数(“outcomes”)—— 260,819
。我们可以看到已经被计算出来的 《白鲸记》 中的总的词数(“outcomes”)—— 260,819![[2]](/uploads/projects/1594/65794.jpg) 。表达式
。表达式most_common(50) 给出文本中 50 个出现频率最高的单词类型![[3]](/uploads/projects/1594/65795.jpg) 。
。
注意
轮到你来:使用text2尝试前面的频率分布的例子。注意正确使用括号和大写字母。如果你得到一个错误消息NameError: name 'FreqDist' is not defined,你需要在一开始输入from nltk.book import *
上一个例子中是否有什么词有助于我们把握这个文本的主题或风格呢?只有一个词,whale,稍微有些信息量!它出现了超过 900 次。其余的词没有告诉我们关于文本的信息;它们只是“管道”英语。这些词在文本中占多少比例?我们可以产生一个这些词汇的累积频率图,使用fdist1.plot(50, cumulative=True) 来生成3.2 中的图。这 50 个词占了书的将近一半!
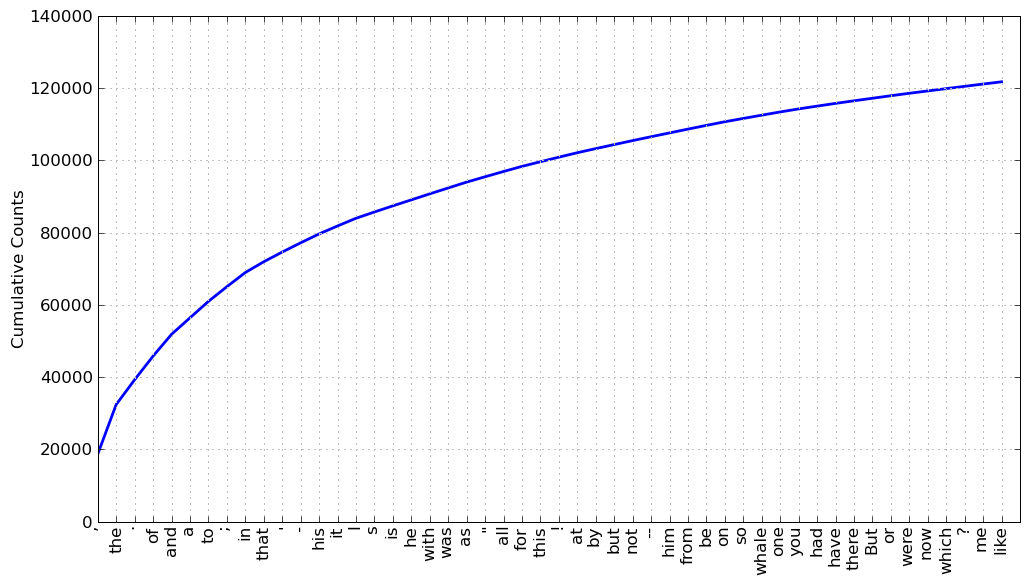
图 3.2: 《白鲸记》 中 50 个最常用词的累积频率图:这些词占了所有词符的将近一半。
如果高频词对我们没有帮助,那些只出现了一次的词(所谓的 hapaxes)又如何呢?输入fdist1.hapaxes() 来查看它们。这个列表包含 lexicographer, cetological, contraband, expostulations 以及其他 9,000 多个。看来低频词太多了,没看到上下文我们很可能有一半的 hapaxes 猜不出它们的意义!既然高频词和低频词都没有帮助,我们需要尝试其他的办法。
