- 1.5 就职演说语料库
1.5 就职演说语料库
在第1章,我们看到了就职演说语料库,但是把它当作一个单独的文本对待。图fig-inaugural中使用的“词偏移”就像是一个坐标轴;它是语料库中词的索引数,从第一个演讲的第一个词开始算起。然而,语料库实际上是 55 个文本的集合,每个文本都是一个总统的演说。这个集合的一个有趣特性是它的时间维度:
>>> from nltk.corpus import inaugural>>> inaugural.fileids()['1789-Washington.txt', '1793-Washington.txt', '1797-Adams.txt', ...]>>> [fileid[:4] for fileid in inaugural.fileids()]['1789', '1793', '1797', '1801', '1805', '1809', '1813', '1817', '1821', ...]
请注意,每个文本的年代都出现在它的文件名中。要从文件名中获得年代,我们使用fileid[:4]提取前四个字符。
让我们来看看词汇 America 和 citizen 随时间推移的使用情况。下面的代码使用w.lower() ![[1]](/uploads/projects/1594/65802.jpg) 将就职演说语料库中的词汇转换成小写,然后用
将就职演说语料库中的词汇转换成小写,然后用startswith() 检查它们是否以“目标”词汇america 或citizen开始。因此,它会计算如 American’s 和 Citizens 等词。我们将在第2节学习条件频率分布,现在只考虑输出,如图1.1所示。
>>> cfd = nltk.ConditionalFreqDist(... (target, fileid[:4])... for fileid in inaugural.fileids()... for w in inaugural.words(fileid)... for target in ['america', 'citizen']... if w.lower().startswith(target)) ![[1]](/projects/nlp-py-2e-zh/Images/eeff7ed83be48bf40aeeb3bf9db5550e.jpg)>>> cfd.plot()
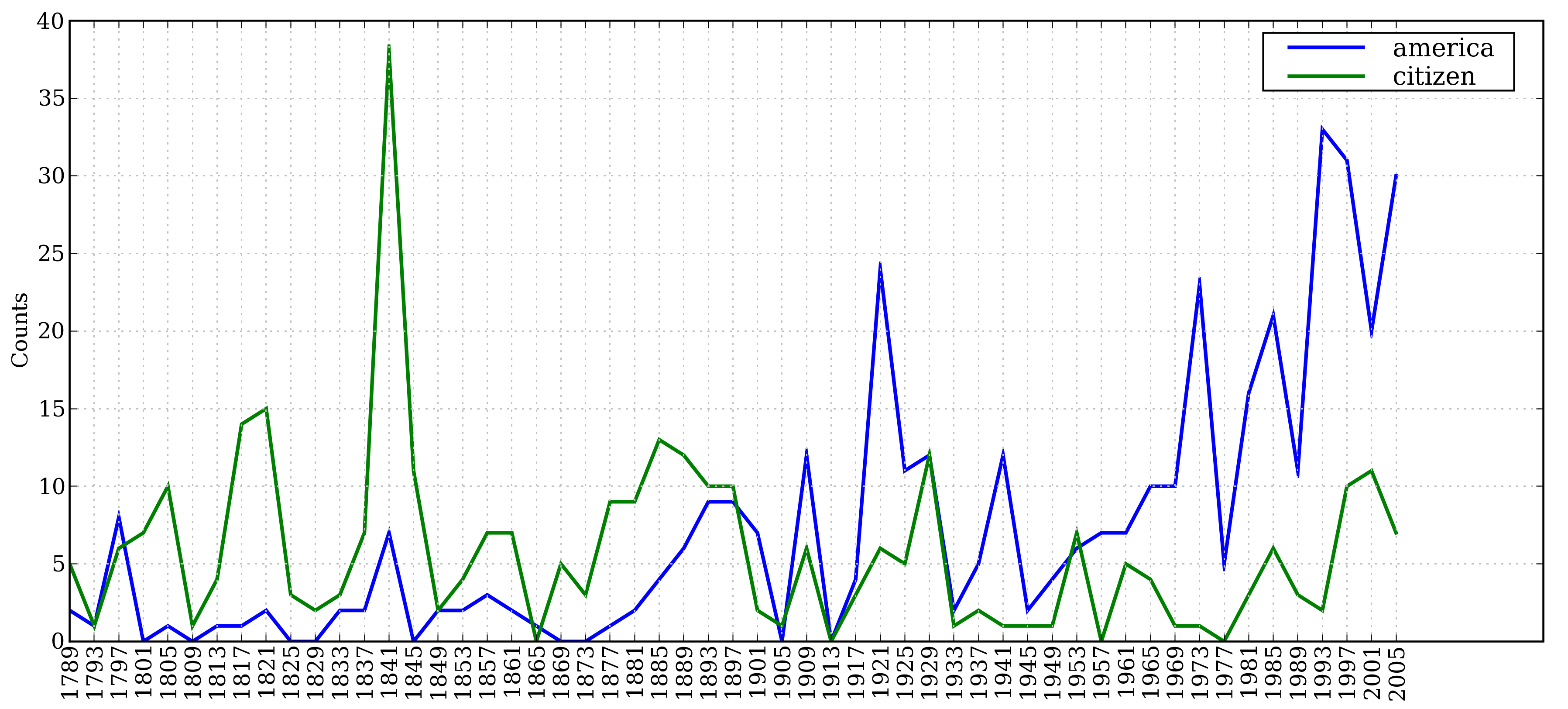
图 1.1:条件频率分布图:计数就职演说语料库中所有以america 或citizen开始的词;每个演讲单独计数;这样就能观察出随时间变化用法上的演变趋势;计数没有与文档长度进行归一化处理。
