- 5.1 段落表示理论
5.1 段落表示理论
一阶逻辑中的量化的标准方法仅限于单个句子。然而,似乎是有量词的范围可以扩大到两个或两个以上的句子的例子。。我们之前看到过一个,下面是第二个例子,与它的翻译一起。
([x, y], [angus(x), dog(y), own(x,y)])
我们可以使用draw()方法![[1]](/uploads/projects/1594/65932.jpg) 可视化结果,如5.2所示。
可视化结果,如5.2所示。
>>> drs1.draw() ![[1]](/projects/nlp-py-2e-zh/Images/ab3d4c917ad3461f18759719a288afa5.jpg)
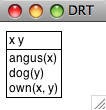
图 5.2:DRS 截图
我们讨论5.1中 DRS 的真值条件时,假设最上面的段落指称被解释为存在量词,而条件也进行了解释,虽然它们是联合的。事实上,每一个 DRS 都可以转化为一阶逻辑公式,fol()方法实现这种转换。
>>> print(drs1.fol())exists x y.(angus(x) & dog(y) & own(x,y))
作为一阶逻辑表达式功能补充,DRT表达式有 DRS-连接运算符,用+符号表示。两个 DRS 的连接是一个单独的 DRS 包含合并的段落指称和来自两个论证的条件。DRS-连接自动进行α-转换绑定变量避免名称冲突。
>>> drs2 = read_dexpr('([x], [walk(x)]) + ([y], [run(y)])')>>> print(drs2)(([x],[walk(x)]) + ([y],[run(y)]))>>> print(drs2.simplify())([x,y],[walk(x), run(y)])
虽然迄今为止见到的所有条件都是原子的,一个 DRS 可以内嵌入另一个 DRS,这是全称量词被处理的方式。在drs3中,没有顶层的段落指称,唯一的条件是由两个子 DRS 组成,通过蕴含连接。再次,我们可以使用fol()来获得真值条件的句柄。
>>> drs3 = read_dexpr('([], [(([x], [dog(x)]) -> ([y],[ankle(y), bite(x, y)]))])')>>> print(drs3.fol())all x.(dog(x) -> exists y.(ankle(y) & bite(x,y)))
我们较早前指出 DRT 旨在通过链接照应代词和现有的段落指称来解释照应代词。DRT 设置约束条件使段落指称可以像先行词那样“可访问”,但并不打算解释一个特殊的先行词如何被从候选集合中选出的。模块nltk.sem.drt_resolve_anaphora采用了类此的保守策略:如果 DRS 包含PRO(x)形式的条件,方法resolve_anaphora()将其替换为x = [...]形式的条件,其中[...]是一个可能的先行词列表。
>>> drs4 = read_dexpr('([x, y], [angus(x), dog(y), own(x, y)])')>>> drs5 = read_dexpr('([u, z], [PRO(u), irene(z), bite(u, z)])')>>> drs6 = drs4 + drs5>>> print(drs6.simplify())([u,x,y,z],[angus(x), dog(y), own(x,y), PRO(u), irene(z), bite(u,z)])>>> print(drs6.simplify().resolve_anaphora())([u,x,y,z],[angus(x), dog(y), own(x,y), (u = [x,y,z]), irene(z), bite(u,z)])
由于指代消解算法已分离到它自己的模块,这有利于在替代程序中交换,使对正确的先行词的猜测更加智能。
我们对 DRS 的处理与处理λ-抽象的现有机制是完全兼容的,因此可以直接基于 DRT 而不是一阶逻辑建立组合语义表示。这种技术在下面的不确定性规则(是语法drt.fcfg的一部分)中说明。为便于比较,我们已经从simple-sem.fcfg增加了不确定性的平行规则。
Det[num=sg,SEM=<\P Q.(([x],[]) + P(x) + Q(x))>] -> 'a'Det[num=sg,SEM=<\P Q. exists x.(P(x) & Q(x))>] -> 'a'
