- 4.3 查询标注器
4.3 查询标注器
很多高频词没有NN标记。让我们找出 100 个最频繁的词,存储它们最有可能的标记。然后我们可以使用这个信息作为“查找标注器”(NLTK UnigramTagger)的模型:
>>> fd = nltk.FreqDist(brown.words(categories='news'))>>> cfd = nltk.ConditionalFreqDist(brown.tagged_words(categories='news'))>>> most_freq_words = fd.most_common(100)>>> likely_tags = dict((word, cfd[word].max()) for (word, _) in most_freq_words)>>> baseline_tagger = nltk.UnigramTagger(model=likely_tags)>>> baseline_tagger.evaluate(brown_tagged_sents)0.45578495136941344
现在应该并不奇怪,仅仅知道 100 个最频繁的词的标记就使我们能正确标注很大一部分词符(近一半,事实上)。让我们来看看它在一些未标注的输入文本上做的如何:
>>> sent = brown.sents(categories='news')[3]>>> baseline_tagger.tag(sent)[('``', '``'), ('Only', None), ('a', 'AT'), ('relative', None),('handful', None), ('of', 'IN'), ('such', None), ('reports', None),('was', 'BEDZ'), ('received', None), ("''", "''"), (',', ','),('the', 'AT'), ('jury', None), ('said', 'VBD'), (',', ','),('``', '``'), ('considering', None), ('the', 'AT'), ('widespread', None),('interest', None), ('in', 'IN'), ('the', 'AT'), ('election', None),(',', ','), ('the', 'AT'), ('number', None), ('of', 'IN'),('voters', None), ('and', 'CC'), ('the', 'AT'), ('size', None),('of', 'IN'), ('this', 'DT'), ('city', None), ("''", "''"), ('.', '.')]
许多词都被分配了一个None标签,因为它们不在 100 个最频繁的词之中。在这些情况下,我们想分配默认标记NN。换句话说,我们要先使用查找表,如果它不能指定一个标记就使用默认标注器,这个过程叫做回退(5)。我们可以做到这个,通过指定一个标注器作为另一个标注器的参数,如下所示。现在查找标注器将只存储名词以外的词的词-标记对,只要它不能给一个词分配标记,它将会调用默认标注器。
>>> baseline_tagger = nltk.UnigramTagger(model=likely_tags,... backoff=nltk.DefaultTagger('NN'))
让我们把所有这些放在一起,写一个程序来创建和评估具有一定范围的查找标注器 ,4.1。
def performance(cfd, wordlist):lt = dict((word, cfd[word].max()) for word in wordlist)baseline_tagger = nltk.UnigramTagger(model=lt, backoff=nltk.DefaultTagger('NN'))return baseline_tagger.evaluate(brown.tagged_sents(categories='news'))def display():import pylabword_freqs = nltk.FreqDist(brown.words(categories='news')).most_common()words_by_freq = [w for (w, _) in word_freqs]cfd = nltk.ConditionalFreqDist(brown.tagged_words(categories='news'))sizes = 2 ** pylab.arange(15)perfs = [performance(cfd, words_by_freq[:size]) for size in sizes]pylab.plot(sizes, perfs, '-bo')pylab.title('Lookup Tagger Performance with Varying Model Size')pylab.xlabel('Model Size')pylab.ylabel('Performance')pylab.show()
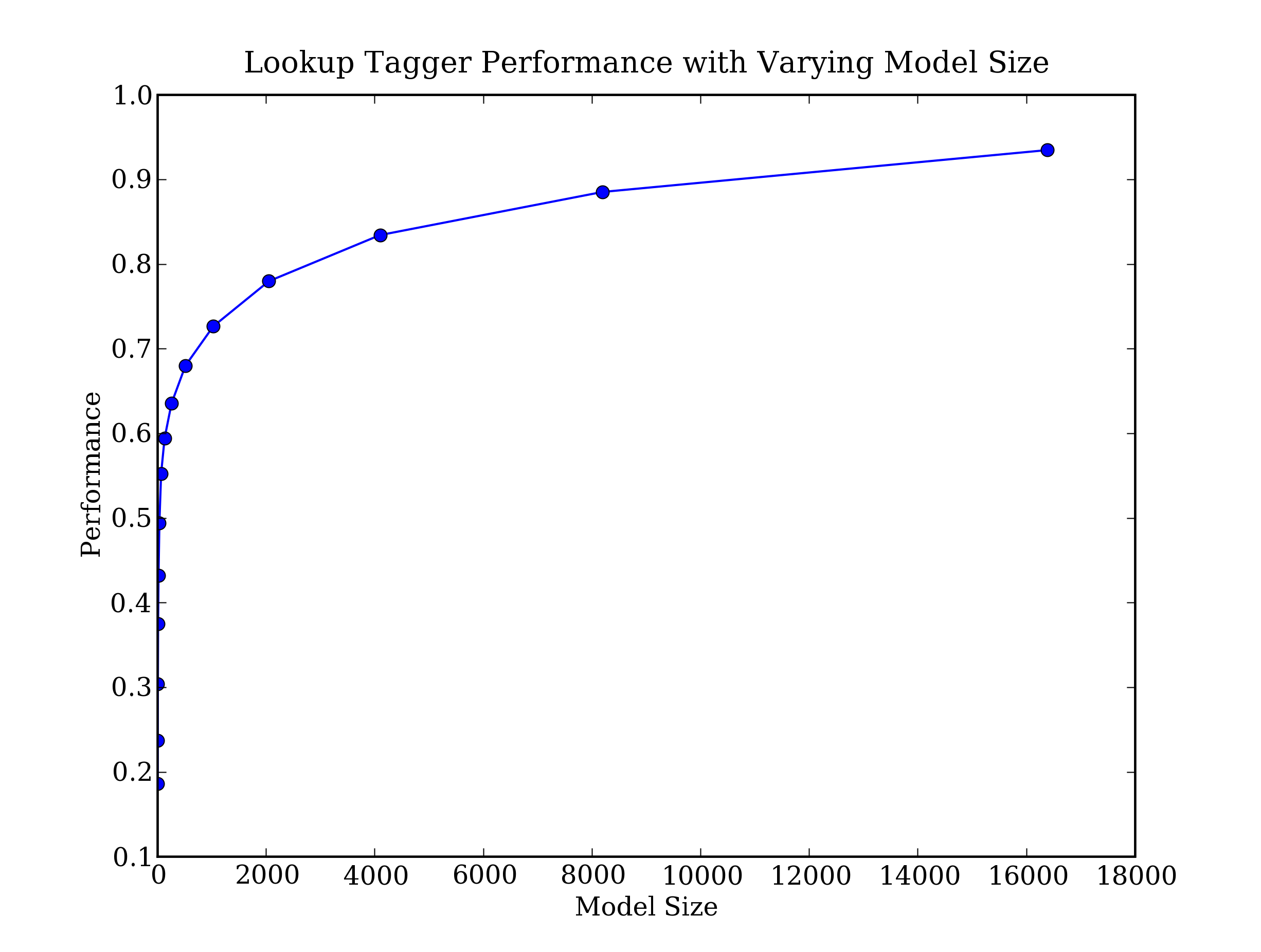
图 4.2:查找标注器
可以观察到,随着模型规模的增长,最初的性能增加迅速,最终达到一个稳定水平,这时模型的规模大量增加性能的提高很小。(这个例子使用pylab绘图软件包,在4.8讨论过)。
