- 16.5 AlphaGo原理浅析
16.5 AlphaGo原理浅析
本篇一开始便提到强化学习是AlphaGo的核心技术之一,刚好借着这个东风将AlphaGo的工作原理了解一番。正如人类下棋那般“手下一步棋,心想三步棋”,Alphago也正是这个思想,当处于一个状态时,机器会暗地里进行多次的尝试/采样,并基于反馈回来的结果信息改进估值函数,从而最终通过增强版的估值函数来选择最优的落子动作。
其中便涉及到了三个主要的问题:(1)如何确定估值函数(2)如何进行采样(3)如何基于反馈信息改进估值函数,这正对应着AlphaGo的三大核心模块:深度学习、蒙特卡罗搜索树、强化学习。
1.深度学习(拟合估值函数)
由于围棋的状态空间巨大,像蒙特卡罗强化学习那样通过采样来确定值函数就行不通了。在围棋中,状态值函数可以看作为一种局面函数,状态-动作值函数可以看作一种策略函数,若我们能获得这两个估值函数,便可以根据这两个函数来完成:(1)衡量当前局面的价值;(2)选择当前最优的动作。那如何精确地估计这两个估值函数呢?这就用到了深度学习,通过大量的对弈数据自动学习出特征,从而拟合出估值函数。
2.蒙特卡罗搜索树(采样)
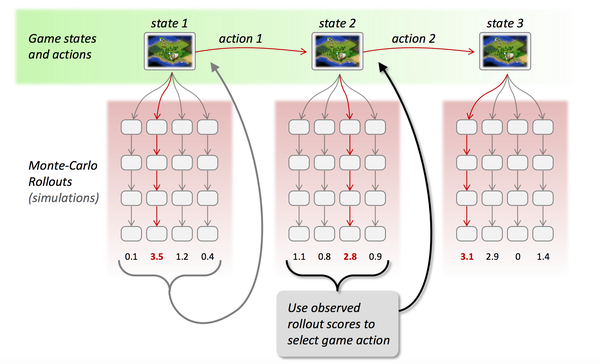
蒙特卡罗树是一种经典的搜索框架,它通过反复地采样模拟对局来探索状态空间。具体表现在:从当前状态开始,利用策略函数尽可能选择当前最优的动作,同时也引入随机性来减小估值错误带来的负面影响,从而模拟棋局运行,使得棋盘达到终局或一定步数后停止。
3.强化学习(调整估值函数)
在使用蒙特卡罗搜索树进行多次采样后,每次采样都会反馈后续的局面信息(利用局面函数进行评价),根据反馈回来的结果信息自动调整两个估值函数的参数,这便是强化学习的核心思想,最后基于改进后的策略函数选择出当前最优的落子动作。
在此,强化学习就介绍完毕。同时也意味着大口小口地啃完了这个西瓜,十分记得去年双11之后立下这个Flag,现在回想起来,大半年的时间里在嚼瓜上还是花费了不少功夫。有人说:当你阐述的能让别人看懂才算是真的理解,有人说:在写的过程中能发现那些只看书发现不了的东西,自己最初的想法十分简单:当健忘症发作的时候,如果能看到之前按照自己思路写下的文字,回忆便会汹涌澎湃一些~
最后,感谢自己这大半年以来的坚持~Get busy living, or get busy dying!
