- 12.2 过滤式选择(Relief)
12.2 过滤式选择(Relief)
过滤式方法是一种将特征选择与学习器训练相分离的特征选择技术,即首先将相关特征挑选出来,再使用选择出的数据子集来训练学习器。Relief是其中著名的代表性算法,它使用一个“相关统计量”来度量特征的重要性,该统计量是一个向量,其中每个分量代表着相应特征的重要性,因此我们最终可以根据这个统计量各个分量的大小来选择出合适的特征子集。
易知Relief算法的核心在于如何计算出该相关统计量。对于数据集中的每个样例xi,Relief首先找出与xi同类别的最近邻与不同类别的最近邻,分别称为猜中近邻(near-hit)与猜错近邻(near-miss),接着便可以分别计算出相关统计量中的每个分量。对于j分量:
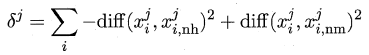
直观上理解:对于猜中近邻,两者j属性的距离越小越好,对于猜错近邻,j属性距离越大越好。更一般地,若xi为离散属性,diff取海明距离,即相同取0,不同取1;若xi为连续属性,则diff为曼哈顿距离,即取差的绝对值。分别计算每个分量,最终取平均便得到了整个相关统计量。
标准的Relief算法只用于二分类问题,后续产生的拓展变体Relief-F则解决了多分类问题。对于j分量,新的计算公式如下:
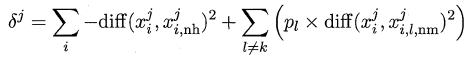
其中pl表示第l类样本在数据集中所占的比例,易知两者的不同之处在于:标准Relief 只有一个猜错近邻,而Relief-F有多个猜错近邻。
