- 14、半监督学习
上篇主要介绍了机器学习的理论基础,首先从独立同分布引入泛化误差与经验误差,接着介绍了PAC可学习的基本概念,即以较大的概率学习出与目标概念近似的假设(泛化误差满足预设上限),对于有限假设空间:(1)可分情形时,假设空间都是PAC可学习的,即当样本满足一定的数量之后,总是可以在与训练集一致的假设中找出目标概念的近似;(2)不可分情形时,假设空间都是不可知PAC可学习的,即以较大概率学习出与当前假设空间中泛化误差最小的假设的有效近似(Hoeffding不等式)。对于无限假设空间,通过增长函数与VC维来描述其复杂度,若学习算法满足经验风险最小化原则,则任何VC维有限的假设空间都是(不可知)PAC可学习的,同时也给出了泛化误差界与样本复杂度。稳定性则考察的是输入发生变化时输出的波动,稳定性通过损失函数与假设空间的可学习理论联系在了一起。本篇将讨论一种介于监督与非监督学习之间的学习算法—半监督学习。
14、半监督学习
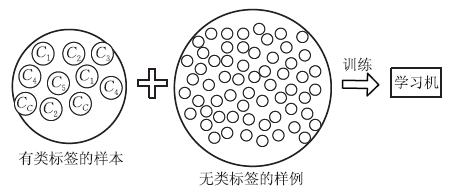
前面我们一直围绕的都是监督学习与无监督学习,监督学习指的是训练样本包含标记信息的学习任务,例如:常见的分类与回归算法;无监督学习则是训练样本不包含标记信息的学习任务,例如:聚类算法。在实际生活中,常常会出现一部分样本有标记和较多样本无标记的情形,例如:做网页推荐时需要让用户标记出感兴趣的网页,但是少有用户愿意花时间来提供标记。若直接丢弃掉无标记样本集,使用传统的监督学习方法,常常会由于训练样本的不充足,使得其刻画总体分布的能力减弱,从而影响了学习器泛化性能。那如何利用未标记的样本数据呢?
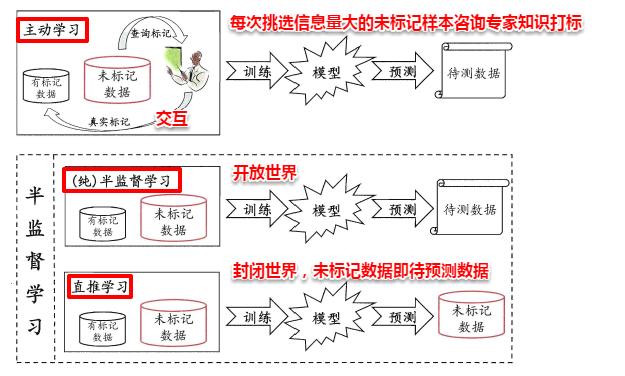
一种简单的做法是通过专家知识对这些未标记的样本进行打标,但随之而来的就是巨大的人力耗费。若我们先使用有标记的样本数据集训练出一个学习器,再基于该学习器对未标记的样本进行预测,从中挑选出不确定性高或分类置信度低的样本来咨询专家并进行打标,最后使用扩充后的训练集重新训练学习器,这样便能大幅度降低标记成本,这便是主动学习(active learning),其目标是使用尽量少的/有价值的咨询来获得更好的性能。
显然,主动学习需要与外界进行交互/查询/打标,其本质上仍然属于一种监督学习。事实上,无标记样本虽未包含标记信息,但它们与有标记样本一样都是从总体中独立同分布采样得到,因此它们所包含的数据分布信息对学习器的训练大有裨益。如何让学习过程不依赖外界的咨询交互,自动利用未标记样本所包含的分布信息的方法便是半监督学习(semi-supervised learning),即训练集同时包含有标记样本数据和未标记样本数据。
此外,半监督学习还可以进一步划分为纯半监督学习和直推学习,两者的区别在于:前者假定训练数据集中的未标记数据并非待预测数据,而后者假定学习过程中的未标记数据就是待预测数据。主动学习、纯半监督学习以及直推学习三者的概念如下图所示: