- 3.3 文件和操作系统
- 文件的字节和Unicode
- 文件的字节和Unicode
3.3 文件和操作系统
本书的代码示例大多使用诸如pandas.read_csv之类的高级工具将磁盘上的数据文件读入Python数据结构。但我们还是需要了解一些有关Python文件处理方面的基础知识。好在它本来就很简单,这也是Python在文本和文件处理方面的如此流行的原因之一。
为了打开一个文件以便读写,可以使用内置的open函数以及一个相对或绝对的文件路径:
In [207]: path = 'examples/segismundo.txt'In [208]: f = open(path)
默认情况下,文件是以只读模式(’r’)打开的。然后,我们就可以像处理列表那样来处理这个文件句柄f了,比如对行进行迭代:
for line in f:pass
从文件中取出的行都带有完整的行结束符(EOL),因此你常常会看到下面这样的代码(得到一组没有EOL的行):
In [209]: lines = [x.rstrip() for x in open(path)]In [210]: linesOut[210]:['Sueña el rico en su riqueza,','que más cuidados le ofrece;','','sueña el pobre que padece','su miseria y su pobreza;','','sueña el que a medrar empieza,','sueña el que afana y pretende,','sueña el que agravia y ofende,','','y en el mundo, en conclusión,','todos sueñan lo que son,','aunque ninguno lo entiende.','']
如果使用open创建文件对象,一定要用close关闭它。关闭文件可以返回操作系统资源:
In [211]: f.close()
用with语句可以可以更容易地清理打开的文件:
In [212]: with open(path) as f:.....: lines = [x.rstrip() for x in f]
这样可以在退出代码块时,自动关闭文件。
如果输入f =open(path,’w’),就会有一个新文件被创建在examples/segismundo.txt,并覆盖掉该位置原来的任何数据。另外有一个x文件模式,它可以创建可写的文件,但是如果文件路径存在,就无法创建。表3-3列出了所有的读/写模式。

对于可读文件,一些常用的方法是read、seek和tell。read会从文件返回字符。字符的内容是由文件的编码决定的(如UTF-8),如果是二进制模式打开的就是原始字节:
In [213]: f = open(path)In [214]: f.read(10)Out[214]: 'Sueña el r'In [215]: f2 = open(path, 'rb') # Binary modeIn [216]: f2.read(10)Out[216]: b'Sue\xc3\xb1a el '
read模式会将文件句柄的位置提前,提前的数量是读取的字节数。tell可以给出当前的位置:
In [217]: f.tell()Out[217]: 11In [218]: f2.tell()Out[218]: 10
尽管我们从文件读取了10个字符,位置却是11,这是因为用默认的编码用了这么多字节才解码了这10个字符。你可以用sys模块检查默认的编码:
In [219]: import sysIn [220]: sys.getdefaultencoding()Out[220]: 'utf-8'
seek将文件位置更改为文件中的指定字节:
In [221]: f.seek(3)Out[221]: 3In [222]: f.read(1)Out[222]: 'ñ'
最后,关闭文件:
In [223]: f.close()In [224]: f2.close()
向文件写入,可以使用文件的write或writelines方法。例如,我们可以创建一个无空行版的prof_mod.py:
In [225]: with open('tmp.txt', 'w') as handle:.....: handle.writelines(x for x in open(path) if len(x) > 1)In [226]: with open('tmp.txt') as f:.....: lines = f.readlines()In [227]: linesOut[227]:['Sueña el rico en su riqueza,\n','que más cuidados le ofrece;\n','sueña el pobre que padece\n','su miseria y su pobreza;\n','sueña el que a medrar empieza,\n','sueña el que afana y pretende,\n','sueña el que agravia y ofende,\n','y en el mundo, en conclusión,\n','todos sueñan lo que son,\n','aunque ninguno lo entiende.\n']
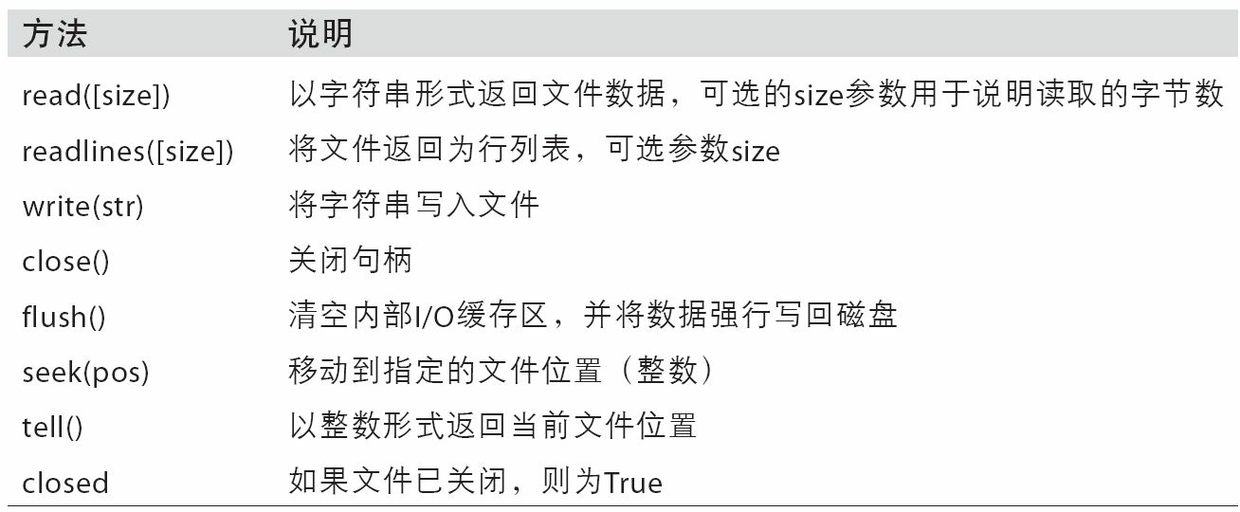
表3-4列出了一些最常用的文件方法。
文件的字节和Unicode
Python文件的默认操作是“文本模式”,也就是说,你需要处理Python的字符串(即Unicode)。它与“二进制模式”相对,文件模式加一个b。我们来看上一节的文件(UTF-8编码、包含非ASCII字符):
In [230]: with open(path) as f:.....: chars = f.read(10)In [231]: charsOut[231]: 'Sueña el r'
UTF-8是长度可变的Unicode编码,所以当我从文件请求一定数量的字符时,Python会从文件读取足够多(可能少至10或多至40字节)的字节进行解码。如果以“rb”模式打开文件,则读取确切的请求字节数:
In [232]: with open(path, 'rb') as f:.....: data = f.read(10)In [233]: dataOut[233]: b'Sue\xc3\xb1a el '
取决于文本的编码,你可以将字节解码为str对象,但只有当每个编码的Unicode字符都完全成形时才能这么做:
In [234]: data.decode('utf8')Out[234]: 'Sueña el 'In [235]: data[:4].decode('utf8')---------------------------------------------------------------------------UnicodeDecodeError Traceback (most recent call last)<ipython-input-235-300e0af10bb7> in <module>()----> 1 data[:4].decode('utf8')UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 3: unexpected end of data
文本模式结合了open的编码选项,提供了一种更方便的方法将Unicode转换为另一种编码:
In [236]: sink_path = 'sink.txt'In [237]: with open(path) as source:.....: with open(sink_path, 'xt', encoding='iso-8859-1') as sink:.....: sink.write(source.read())In [238]: with open(sink_path, encoding='iso-8859-1') as f:.....: print(f.read(10))Sueña el r
注意,不要在二进制模式中使用seek。如果文件位置位于定义Unicode字符的字节的中间位置,读取后面会产生错误:
In [240]: f = open(path)In [241]: f.read(5)Out[241]: 'Sueña'In [242]: f.seek(4)Out[242]: 4In [243]: f.read(1)---------------------------------------------------------------------------UnicodeDecodeError Traceback (most recent call last)<ipython-input-243-7841103e33f5> in <module>()----> 1 f.read(1)/miniconda/envs/book-env/lib/python3.6/codecs.py in decode(self, input, final)319 # decode input (taking the buffer into account)320 data = self.buffer + input--> 321 (result, consumed) = self._buffer_decode(data, self.errors, final)322 # keep undecoded input until the next call323 self.buffer = data[consumed:]UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb1 in position 0: invalid start byteIn [244]: f.close()
如果你经常要对非ASCII字符文本进行数据分析,通晓Python的Unicode功能是非常重要的。更多内容,参阅Python官方文档。
