- 代码示例
代码示例
让我们使用加仑公里数这个数据集,格式如下:
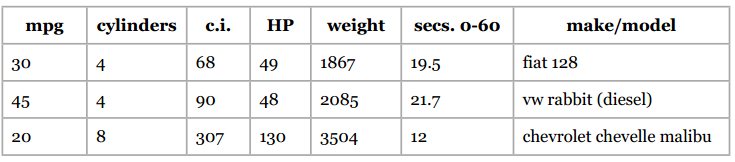
我会通过汽车的以下属性来判断它的加仑公里数:汽缸数、排气量、马力、重量、加速度。我将392条数据都存放在mpgData.txt文件中,并用下面这段Python代码将这些数据按层次等分成十份:
# -*- coding: utf-8 -*-## 将数据等分成十份的示例代码import randomdef buckets(filename, bucketName, separator, classColumn):"""filename是源文件名bucketName是十个目标文件的前缀名separator是分隔符,如制表符、逗号等classColumn是表示数据所属分类的那一列的序号"""# 将数据分为10份numberOfBuckets = 10data = {}# 读取数据,并按分类放置with open(filename) as f:lines = f.readlines()for line in lines:if separator != '\t':line = line.replace(separator, '\t')# 获取分类category = line.split()[classColumn]data.setdefault(category, [])data[category].append(line)# 初始化分桶buckets = []for i in range(numberOfBuckets):buckets.append([])# 将各个类别的数据均匀地放置到桶中for k in data.keys():# 打乱分类顺序random.shuffle(data[k])bNum = 0# 分桶for item in data[k]:buckets[bNum].append(item)bNum = (bNum + 1) % numberOfBuckets# 写入文件for bNum in range(numberOfBuckets):f = open("%s-%02i" % (bucketName, bNum + 1), 'w')for item in buckets[bNum]:f.write(item)f.close()# 调用示例buckets("pimaSmall.txt", 'pimaSmall',',',8)
执行这个程序后会生成10个文件:mpgData01、mpgData02等。
编程实践
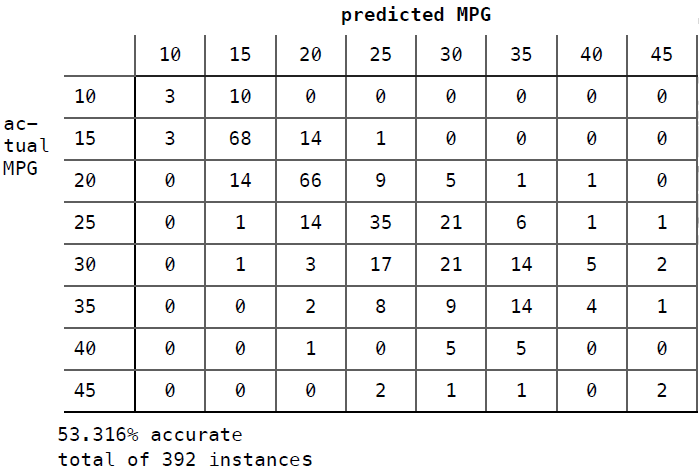
你能否修改上一章的近邻算法程序,让test函数能够执行十折交叉验证?输出的结果应该是这样的:
解决方案
我们需要进行以下几步:
- 修改初始化方法,只读取九个桶中的数据作为训练集;
- 增加一个方法,从第十个桶中读取测试集;
- 执行十折交叉验证。
下面我们分步来看:
- 初始化方法
__init__
__init__方法的签名会修改成以下形式:
def __init__(self, bucketPrefix, testBucketNumber, dataFormat):
每个桶的文件名是mpgData-01、mpgData-02这样的形式,所以bucketPrefix就是“mpgData”。testBucketNumber是测试集所用的桶,如果是3,则分类器会使用1、2、4-9的桶进行训练。dataFormat用来指定数据集的格式,如:
class num num num num num comment
意味着第一列是所属分类,后五列是特征值,最后一列是备注信息。
以下是初始化方法的示例代码:
class Classifier:def __init__(self, bucketPrefix, testBucketNumber, dataFormat):"""该分类器程序将从bucketPrefix指定的一系列文件中读取数据,并留出testBucketNumber指定的桶来做测试集,其余的做训练集。dataFormat用来表示数据的格式,如:"class num num num num num comment""""self.medianAndDeviation = []# 从文件中读取文件self.format = dataFormat.strip().split('\t')self.data = []# 用1-10来标记桶for i in range(1, 11):# 判断该桶是否包含在训练集中if i != testBucketNumber:filename = "%s-%02i" % (bucketPrefix, i)f = open(filename)lines = f.readlines()f.close()for line in lines[1:]:fields = line.strip().split('\t')ignore = []vector = []for i in range(len(fields)):if self.format[i] == 'num':vector.append(float(fields[i]))elif self.format[i] == 'comment':ignore.append(fields[i])elif self.format[i] == 'class':classification = fields[i]self.data.append((classification, vector, ignore))self.rawData = list(self.data)# 获取特征向量的长度self.vlen = len(self.data[0][1])# 标准化数据for i in range(self.vlen):self.normalizeColumn(i)
- testBucket方法
下面的方法会使用一个桶的数据进行测试:
def testBucket(self, bucketPrefix, bucketNumber):"""读取bucketPrefix-bucketNumber所指定的文件作为测试集"""filename = "%s-%02i" % (bucketPrefix, bucketNumber)f = open(filename)lines = f.readlines()totals = {}f.close()for line in lines:data = line.strip().split('\t')vector = []classInColumn = -1for i in range(len(self.format)):if self.format[i] == 'num':vector.append(float(data[i]))elif self.format[i] == 'class':classInColumn = itheRealClass = data[classInColumn]classifiedAs = self.classify(vector)totals.setdefault(theRealClass, {})totals[theRealClass].setdefault(classifiedAs, 0)totals[theRealClass][classifiedAs] += 1return totals
比如说bucketPrefix是mpgData,bucketNumber是3,那么程序会从mpgData-03中读取内容,作为测试集。这个方法会返回如下形式的结果:
{'35': {'35': 1, '20': 1, '30': 1},'40': {'30': 1},'30': {'35': 3, '30': 1, '45': 1, '25': 1},'15': {'20': 3, '15': 4, '10': 1},'10': {'15': 1},'20': {'15': 2, '20': 4, '30': 2, '25': 1},'25': {'30': 5, '25': 3}}
这个字段的键表示真实类别。如第一行的35表示该行数据的真实类别是35加仑公里。这个键又对应一个字典,这个字典表示的是分类器所判断的类别,如:
'15': {'20': 3, '15': 4, '10': 1},
其中的3表示有3条记录真实类别是15加仑公里,但被分类到了20加仑公里;4表示分类正确的记录数;1表示被分到10加仑公里的记录数。
- 执行十折交叉验证
最后我们需要编写一段程序来执行十折交叉验证,也就是说要用不同的训练集和测试集来构建10个分类器。
def tenfold(bucketPrefix, dataFormat):results = {}for i in range(1, 11):c = Classifier(bucketPrefix, i, dataFormat)t = c.testBucket(bucketPrefix, i)for (key, value) in t.items():results.setdefault(key, {})for (ckey, cvalue) in value.items():results[key].setdefault(ckey, 0)results[key][ckey] += cvalue# 输出结果categories = list(results.keys())categories.sort()print( "\n Classified as: ")header = " "subheader = " +"for category in categories:header += category + " "subheader += "----+"print (header)print (subheader)total = 0.0correct = 0.0for category in categories:row = category + " |"for c2 in categories:if c2 in results[category]:count = results[category][c2]else:count = 0row += " %2i |" % counttotal += countif c2 == category:correct += countprint(row)print(subheader)print("\n%5.3f percent correct" %((correct * 100) / total))print("total of %i instances" % total)# 调用方法tenfold("mpgData/mpgData", "class num num num num num comment")
执行结果如下:
Classified as:10 15 20 25 30 35 40 45+----+----+----+----+----+----+----+----+10 | 3 | 10 | 0 | 0 | 0 | 0 | 0 | 0 |15 | 3 | 68 | 14 | 1 | 0 | 0 | 0 | 0 |20 | 0 | 14 | 66 | 9 | 5 | 1 | 1 | 0 |25 | 0 | 1 | 14 | 35 | 21 | 6 | 1 | 1 |30 | 0 | 1 | 3 | 17 | 21 | 14 | 5 | 2 |35 | 0 | 0 | 2 | 8 | 9 | 14 | 4 | 1 |40 | 0 | 0 | 1 | 0 | 5 | 5 | 0 | 0 |45 | 0 | 0 | 0 | 2 | 1 | 1 | 0 | 2 |+----+----+----+----+----+----+----+----+53.316 percent correcttotal of 392 instances
可以在这里下载代码和数据集。
