 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 7.18.强连通分量
7.18.强连通分量
在本章的剩余部分,我们将把注意力转向一些非常大的图。我们将用来研究一些附加算法的图,由互联网上的主机之间的连接和网页之间的链接产生的图。 我们将从网页开始。
像 Google 和 Bing 这样的搜索引擎利用了网页上的页面形成非常大的有向图。 为了将万维网变换为图,我们将把一个页面视为一个顶点,并将页面上的超链接作为将一个顶点连接到另一个顶点的边缘。 Figure 30 展示了从 Luther College 的计算机科学主页开始,通过跟踪从一页到下一页的链接产生的图的非常小的部分。当然,这个图可能是巨大的,所以我们把它限制在距离 CS 主页不超过 10 个链接的网站。
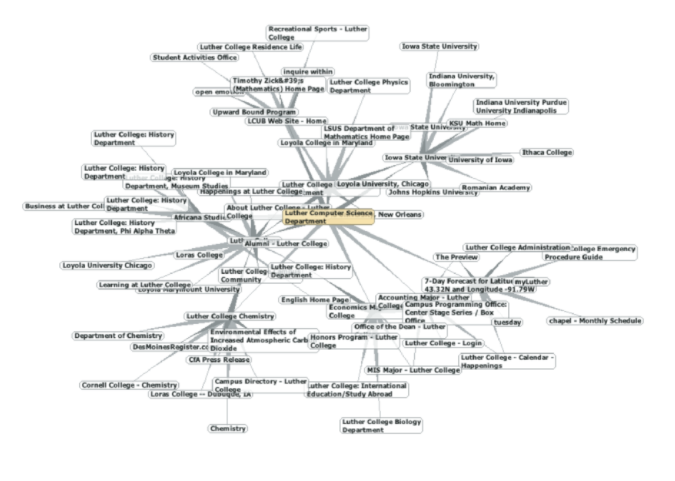
Figure 30
如果你看 Figure 30中的图形,你可能会有一些有趣的观察。首先你可能会注意到,图上的许多其他网站是其他路德学院网站。第二,你可能注意到有几个链接到爱荷华州的其他学院。第三,你可能注意到有几个链接到其他文理学院。你可能会得出这样的结论,网络集群上的网站在一些级别上底层结构类似。
可以帮助找到图中高度互连的顶点的集群的一种图算法被称为强连通分量算法(SCC)。我们正式定义图 G 的强连通分量 C 作为顶点
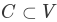 的最大子集,使得对于每对顶点
的最大子集,使得对于每对顶点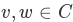 ,我们具有从 v 到 w 的路径和从 w 到 v 的路径。Figure 27 展示了具有三个强连接分量的简单图。强连接分量由不同的阴影区域标识。
,我们具有从 v 到 w 的路径和从 w 到 v 的路径。Figure 27 展示了具有三个强连接分量的简单图。强连接分量由不同的阴影区域标识。
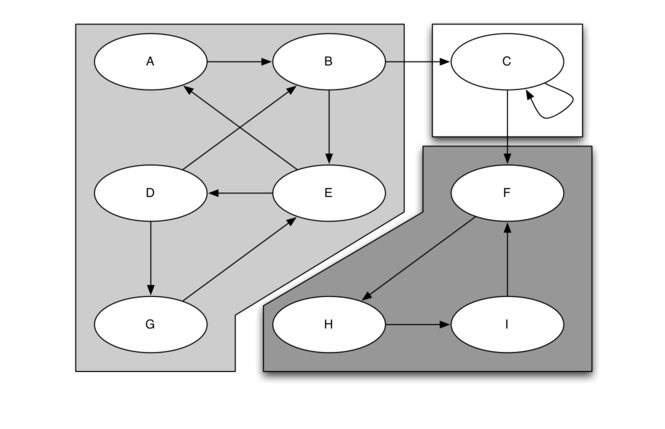
Figure 27
一旦确定了强连通分量,我们就可以通过将一个强连通分量中的所有顶点组合成一个较大的顶点来显示该图的简化视图。 Figure 31中的曲线图的简化版本如 Figure 32所示。
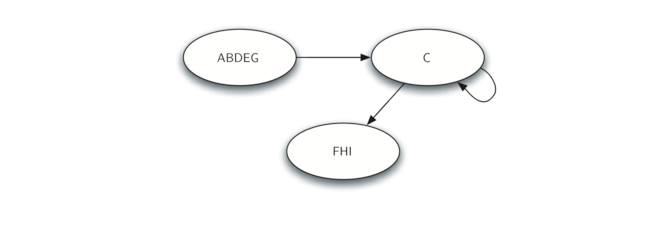
Figure 32
我们再次看到,我们可以通过使用深度优先搜索来创建一个非常强大和高效的算法。 在我们处理主 SCC 算法之前,我们必须考虑另一个定义。 图 G 的转置被定义为图
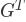 ,其中图中的所有边已经反转。 也就是说,如果在原始图中存在从节点 A 到节点 B 的有向边,则
,其中图中的所有边已经反转。 也就是说,如果在原始图中存在从节点 A 到节点 B 的有向边,则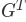 将包含从节点 B 到节点 A 的边。Figure 33和 Figure 34 展示了简单图及其变换。
将包含从节点 B 到节点 A 的边。Figure 33和 Figure 34 展示了简单图及其变换。
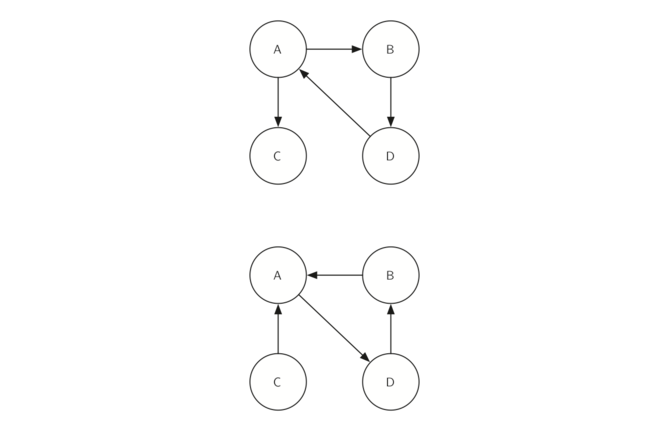
Figure 33-34
再看看数字。 请注意,Figure 33中的图形有两个强连通分量。 现在看看Figure 34。注意它也有两个强连通分量。
我们现在可以描述用于计算图的强连通分量的算法。
- 调用 dfs 为图 G 计算每个顶点的完成时间。
- 计算
 。
。 - 为图
 调用 dfs,但在 DFS 的主循环中,以完成时间的递减顺序探查每个顶点。
调用 dfs,但在 DFS 的主循环中,以完成时间的递减顺序探查每个顶点。 - 在步骤 3 中计算的森林中的每个树是强连通分量。输出森林中每个树中每个顶点的顶点标识组件。让我们在 Figure 31中的示例图上跟踪上述步骤的操作。Figure 35 展示了由 DFS 算法为原始图计算的开始和结束时间。 Figure 36 展示了通过在转置图上运行 DFS 计算的开始和结束时间。
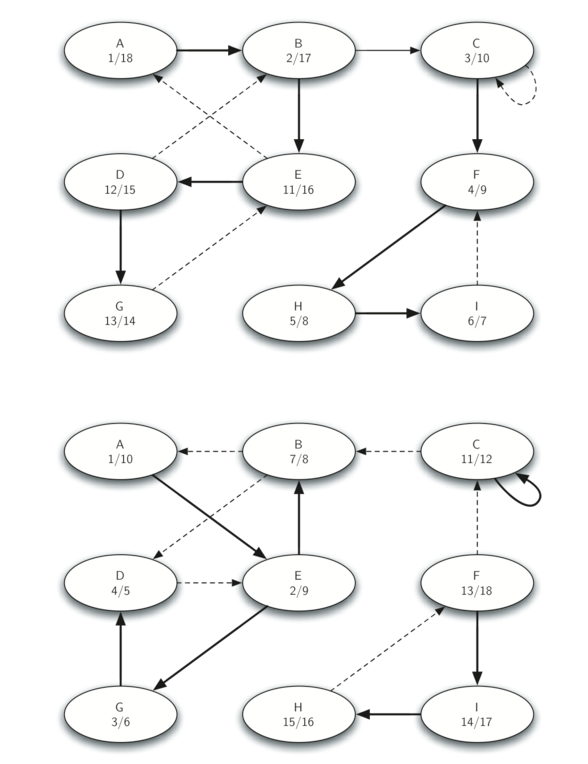
Figure 36
最后,Figure 37 展示了在强连通分量算法的步骤 3 中产生的三棵树的森林。 你会注意到,我们不为你提供 SCC 算法的 Python 代码,我们将此程序作为练习。
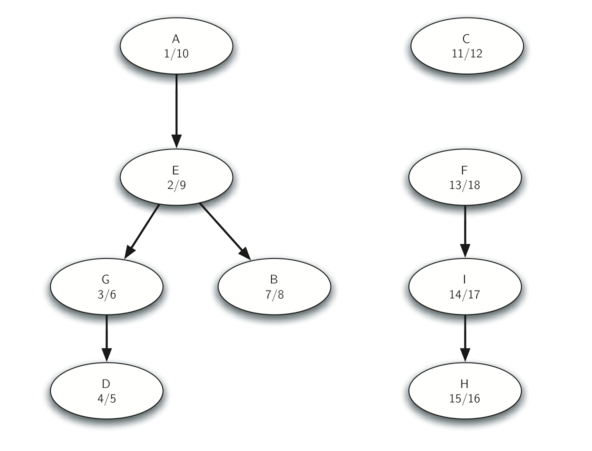
Figure 37
