 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 7.15.通用深度优先搜索
7.15.通用深度优先搜索
骑士之旅是深度优先搜索的特殊情况,其目的是创建最深的第一棵树,没有任何分支。更一般的深度优先搜索实际上更容易。它的目标是尽可能深的搜索,在图中连接尽可能多的节点,并在必要时创建分支。
甚至可能的是,深度优先搜索将创建多于一个树。当深度优先搜索算法创建一组树时,我们称之为深度优先森林。与广度优先搜索一样,我们的深度优先搜索使用前导链接来构造树。此外,深度优先搜索将在顶点类中使用两个附加的实例变量。新实例变量是发现和完成时间。发现时间跟踪首次遇到顶点之前的步骤数。完成时间是顶点着色为黑色之前的步骤数。正如我们看到的算法,节点的发现和完成时间提供了一些有趣的属性,我们可以在以后的算法中使用。
我们深度优先搜索的代码如 Listing 5 所示。由于 dfs 和它的辅助函数dfsvisit 这两个函数使用一个变量来跟踪调用 dfsvisit 的时间,所以我们选择将代码实现为继承自 Graph 类。此实现通过添加时间实例变量和两个方法 dfs 和 dfsvisit来扩展 Graph 类。看看第 11 行,你会注意到,dfs 方法在调用 dfsvisit 的图中所有的顶点迭代,这些节点是白色的。我们迭代所有节点而不是简单地从所选择的起始节点进行搜索的原因是为了确保图中的所有节点都被考虑到,没有顶点从深度优先森林中被遗漏。for aVertex in self 语句可能看起来不寻常,但请记住,在这种情况下,self是 DFSGraph 类的一个实例,遍历实例中的所有顶点是一件自然的事情。
from pythonds.graphs import Graphclass DFSGraph(Graph):def __init__(self):super().__init__()self.time = 0def dfs(self):for aVertex in self:aVertex.setColor('white')aVertex.setPred(-1)for aVertex in self:if aVertex.getColor() == 'white':self.dfsvisit(aVertex)def dfsvisit(self,startVertex):startVertex.setColor('gray')self.time += 1startVertex.setDiscovery(self.time)for nextVertex in startVertex.getConnections():if nextVertex.getColor() == 'white':nextVertex.setPred(startVertex)self.dfsvisit(nextVertex)startVertex.setColor('black')self.time += 1startVertex.setFinish(self.time)
Listing 5
虽然我们 bfs 的实现只对有一条路径回到开始的路径的节点感兴趣,但是有可能创建一个宽度优先森林,其表示图中的所有节点之间的最短路径。我们把这作为一个练习。在接下来的两个算法中,我们将看到为什么跟踪深度优先森林的深度很重要。
dfsvisit 方法从名为 startVertex 的单个顶点开始,并尽可能深地探查所有相邻的白色顶点。如果仔细查看 dfsvisit 的代码并将其与广度优先搜索进行比较,应该注意的是,dfsvisit 算法几乎与 bfs 相同,除了在内部 for 循环的最后一行,dfsvisit 将自行递归调用以继续在更深的级别搜索,而 bfs 将节点添加到队列以供稍后探查。有趣的是,bfs 使用队列,dfsvisit 使用栈。你在代码中没有看到栈,但是它在 dfsvisit 的递归调用中是隐含的。
以下图的序列展示了针对小图的深度优先搜索算法。在这些图中,虚线指示检查的边,但是在边的另一端的节点已经被添加到深度优先树。在代码中,通过检查另一个节点的颜色是非白色的。
搜索从图的顶点 A 开始(Figure 14)。由于所有顶点在搜索开始时都是白色的,所以算法访问顶点 A。访问顶点的第一步是将颜色设置为灰色,这表示正在探索顶点,并且将发现时间设置为1,由于顶点 A 具有两个相邻的顶点(B,D),因此每个顶点也需要被访问。我们将做出任意决定,我们将按字母顺序访问相邻顶点。
接下来访问顶点B(Figure 15),因此其颜色设置为灰色并且其发现时间被设置为 2。顶点 B 也与两个其他节点(C,D)相邻,因此我们将遵循字母顺序和访问节点 C 接下来。
访问顶点 C(Figure16)使我们到树的一个分支的末端。在将节点灰色着色并将其发现时间设置为 3 之后,算法还确定没有与 C 相邻的顶点。这意味着我们完成了对节点 C 的探索,因此我们可以将顶点着色为黑色,并将完成时间设置为 4,在Figure 17 中,可以看到我们的搜索的状态。
由于顶点 C 是一个分支的结束,我们现在返回到顶点 B,继续探索与 B 相邻的节点。从 B 中探索的唯一额外的顶点是 D,所以我们现在可以访问 D(Figure 18),并继续搜索顶点 D。顶点 D 快速引导我们到顶点 E(Figure 19)。顶点 E 具有两个相邻的顶点 B 和 F 。通常我们将按字母顺序探索这些相邻顶点,但是由于 B 已经是灰色的,所以算法识别出它不应该访问 B,因为这样做会将算法置于循环中!因此,继续探索列表中的下一个顶点,即 F(Figure 20)。
顶点 F 只有一个相邻的顶点 C,但由于 C 是黑色的,没有别的东西可以探索,算法已经到达另一个分支的结束。从这里开始,你将在 Figure 21至 Figure 25中看到算法运行回到第一个节点,设置完成时间和着色顶点为黑色。
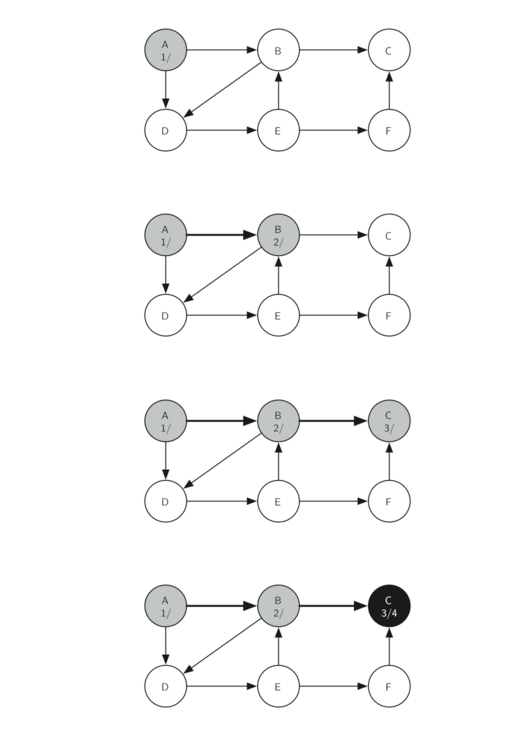
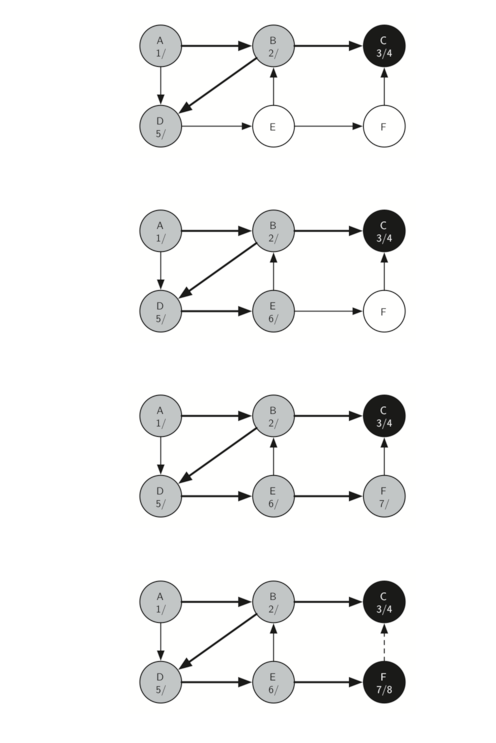
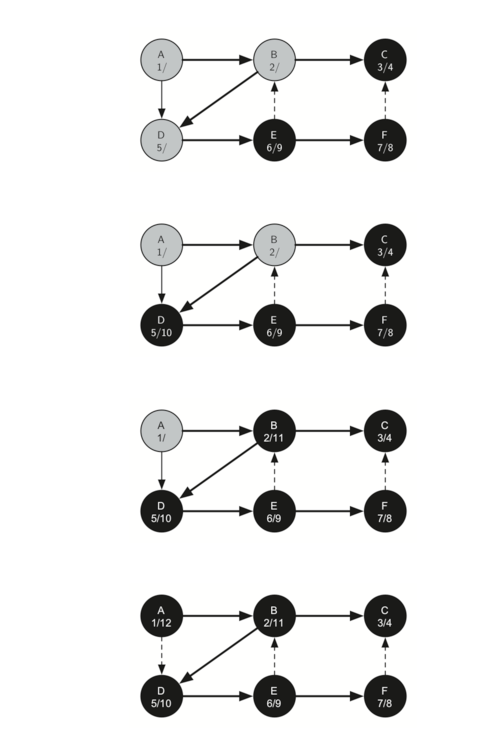
Figure 14-25
每个节点的开始和结束时间展示一个称为 括号属性 的属性。 该属性意味着深度优先树中的特定节点的所有子节点具有比它们的父节点更晚的发现时间和更早的完成时间。 Figure 26 展示了由深度优先搜索算法构造的树。
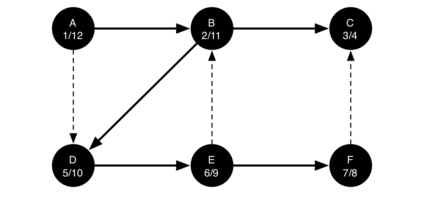
Figure 26
