可视化功能
一旦你的自编码器学习了一些功能,你可能想看看它们。 有各种各样的技术。 可以说最简单的技术是在每个隐藏层中考虑每个神经元,并找到最能激活它的训练实例。 这对顶层隐藏层特别有用,因为它们通常会捕获相对较大的功能,您可以在包含它们的一组训练实例中轻松找到这些功能。 例如,如果神经元在图片中看到一只猫时强烈激活,那么激活它的图片最显眼的地方都会包含猫。 然而,对于较低层,这种技术并不能很好地工作,因为这些特征更小,更抽象,因此很难准确理解神经元正在为什么而兴奋。
让我们看看另一种技术。 对于第一个隐藏层中的每个神经元,您可以创建一个图像,其中像素的强度对应于给定神经元的连接权重。 例如,以下代码绘制了第一个隐藏层中五个神经元学习的特征:
with tf.Session() as sess:[...] # train autoencoderweights1_val = weights1.eval()for i in range(5):plt.subplot(1, 5, i + 1)plot_image(weights1_val.T[i])
您可能会得到如图 15-7 所示的低级功能。
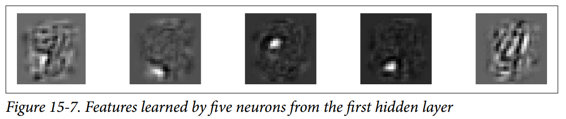
前四个特征似乎对应于小块,而第五个特征似乎寻找垂直笔划(请注意,这些特征来自堆叠去噪自编码器,我们将在后面讨论)。
另一种技术是给自编码器提供一个随机输入图像,测量您感兴趣的神经元的激活,然后执行反向传播来调整图像,使神经元激活得更多。 如果迭代数次(执行渐变上升),图像将逐渐变成最令人兴奋的图像(用于神经元)。 这是一种有用的技术,用于可视化神经元正在寻找的输入类型。
最后,如果使用自编码器执行无监督预训练(例如,对于分类任务),验证自编码器学习的特征是否有用的一种简单方法是测量分类器的性能。
