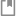 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签非线性支持向量机分类
尽管线性 SVM 分类器在许多案例上表现得出乎意料的好,但是很多数据集并不是线性可分的。一种处理非线性数据集方法是增加更多的特征,例如多项式特征(正如你在第4章所做的那样);在某些情况下可以变成线性可分的数据。在图 5-5的左图中,它只有一个特征x1的简单的数据集,正如你看到的,该数据集不是线性可分的。但是如果你增加了第二个特征 x2=(x1)^2,产生的 2D 数据集就能很好的线性可分。
为了实施这个想法,通过 Scikit-Learn,你可以创建一个流水线(Pipeline)去包含多项式特征(PolynomialFeatures)变换(在 121 页的“Polynomial Regression”中讨论),然后一个StandardScaler和LinearSVC。让我们在卫星数据集(moons datasets)测试一下效果。
from sklearn.datasets import make_moonsfrom sklearn.pipeline import Pipelinefrom sklearn.preprocessing import PolynomialFeaturespolynomial_svm_clf = Pipeline((("poly_features", PolynomialFeatures(degree=3)),("scaler", StandardScaler()),("svm_clf", LinearSVC(C=10, loss="hinge"))))polynomial_svm_clf.fit(X, y)
多项式核
添加多项式特征很容易实现,不仅仅在 SVM,在各种机器学习算法都有不错的表现,但是低次数的多项式不能处理非常复杂的数据集,而高次数的多项式却产生了大量的特征,会使模型变得慢。
幸运的是,当你使用 SVM 时,你可以运用一个被称为“核技巧”(kernel trick)的神奇数学技巧。它可以取得就像你添加了许多多项式,甚至有高次数的多项式,一样好的结果。所以不会大量特征导致的组合爆炸,因为你并没有增加任何特征。这个技巧可以用 SVC 类来实现。让我们在卫星数据集测试一下效果。
from sklearn.svm import SVCpoly_kernel_svm_clf = Pipeline((("scaler", StandardScaler()),("svm_clf", SVC(kernel="poly", degree=3, coef0=1, C=5))))poly_kernel_svm_clf.fit(X, y)
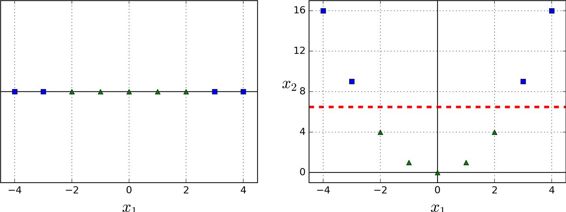
这段代码用3阶的多项式核训练了一个 SVM 分类器,即图 5-7 的左图。右图是使用了10阶的多项式核 SVM 分类器。很明显,如果你的模型过拟合,你可以减小多项式核的阶数。相反的,如果是欠拟合,你可以尝试增大它。超参数coef0控制了高阶多项式与低阶多项式对模型的影响。
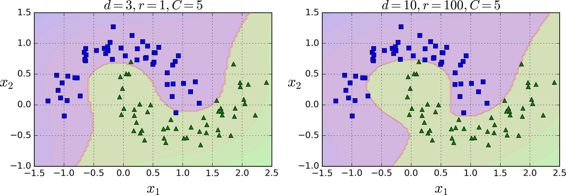
通用的方法是用网格搜索(grid search 见第 2 章)去找到最优超参数。首先进行非常粗略的网格搜索一般会很快,然后在找到的最佳值进行更细的网格搜索。对每个超参数的作用有一个很好的理解可以帮助你在正确的超参数空间找到合适的值。
增加相似特征
另一种解决非线性问题的方法是使用相似函数(similarity funtion)计算每个样本与特定地标(landmark)的相似度。例如,让我们来看看前面讨论过的一维数据集,并在x1=-2和x1=1之间增加两个地标(图 5-8 左图)。接下来,我们定义一个相似函数,即高斯径向基函数(Gaussian Radial Basis Function,RBF),设置γ = 0.3(见公式 5-1)
公式 5-1 RBF
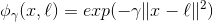
它是个从 0 到 1 的钟型函数,值为 0 的离地标很远,值为 1 的在地标上。现在我们准备计算新特征。例如,我们看一下样本x1=-1:它距离第一个地标距离是 1,距离第二个地标是 2。因此它的新特征为x2=exp(-0.3 × (1^2))≈0.74和x3=exp(-0.3 × (2^2))≈0.30。图 5-8 右边的图显示了特征转换后的数据集(删除了原始特征),正如你看到的,它现在是线性可分了。
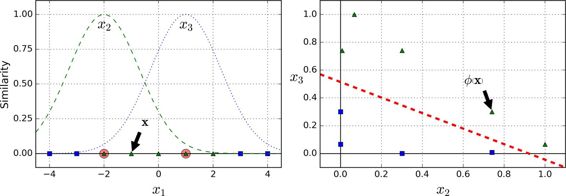
你可能想知道如何选择地标。最简单的方法是在数据集中的每一个样本的位置创建地标。这将产生更多的维度从而增加了转换后数据集是线性可分的可能性。但缺点是,m个样本,n个特征的训练集被转换成了m个实例,m个特征的训练集(假设你删除了原始特征)。这样一来,如果你的训练集非常大,你最终会得到同样大的特征。
高斯 RBF 核
就像多项式特征法一样,相似特征法对各种机器学习算法同样也有不错的表现。但是在所有额外特征上的计算成本可能很高,特别是在大规模的训练集上。然而,“核” 技巧再一次显现了它在 SVM 上的神奇之处:高斯核让你可以获得同样好的结果成为可能,就像你在相似特征法添加了许多相似特征一样,但事实上,你并不需要在RBF添加它们。我们使用 SVC 类的高斯 RBF 核来检验一下。
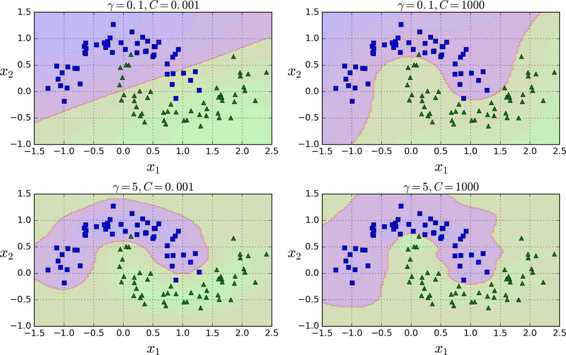
rbf_kernel_svm_clf = Pipeline((("scaler", StandardScaler()),("svm_clf", SVC(kernel="rbf", gamma=5, C=0.001))))rbf_kernel_svm_clf.fit(X, y)
这个模型在图 5-9 的左下角表示。其他的图显示了用不同的超参数gamma (γ)和C训练的模型。增大γ使钟型曲线更窄(图 5-8 左图),导致每个样本的影响范围变得更小:即判定边界最终变得更不规则,在单个样本周围环绕。相反的,较小的γ值使钟型曲线更宽,样本有更大的影响范围,判定边界最终则更加平滑。所以γ是可调整的超参数:如果你的模型过拟合,你应该减小γ值,若欠拟合,则增大γ(与超参数C相似)。
还有其他的核函数,但很少使用。例如,一些核函数是专门用于特定的数据结构。在对文本文档或者 DNA 序列进行分类时,有时会使用字符串核(String kernels)(例如,使用 SSK 核(string subsequence kernel)或者基于编辑距离(Levenshtein distance)的核函数)。
提示
这么多可供选择的核函数,你如何决定使用哪一个?一般来说,你应该先尝试线性核函数(记住
LinearSVC比SVC(kernel="linear")要快得多),尤其是当训练集很大或者有大量的特征的情况下。如果训练集不太大,你也可以尝试高斯径向基核(Gaussian RBF Kernel),它在大多数情况下都很有效。如果你有空闲的时间和计算能力,你还可以使用交叉验证和网格搜索来试验其他的核函数,特别是有专门用于你的训练集数据结构的核函数。
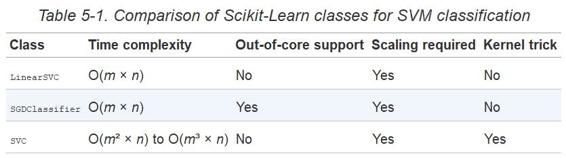
计算复杂性
LinearSVC类基于liblinear库,它实现了线性 SVM 的优化算法。它并不支持核技巧,但是它样本和特征的数量几乎是线性的:训练时间复杂度大约为O(m × n)。
如果你要非常高的精度,这个算法需要花费更多时间。这是由容差值超参数ϵ(在 Scikit-learn 称为tol)控制的。大多数分类任务中,使用默认容差值的效果是已经可以满足一般要求。
SVC 类基于libsvm库,它实现了支持核技巧的算法。训练时间复杂度通常介于O(m^2 × n)和O(m^3 × n)之间。不幸的是,这意味着当训练样本变大时,它将变得极其慢(例如,成千上万个样本)。这个算法对于复杂但小型或中等数量的数据集表现是完美的。然而,它能对特征数量很好的缩放,尤其对稀疏特征来说(sparse features)(即每个样本都有一些非零特征)。在这个情况下,算法对每个样本的非零特征的平均数量进行大概的缩放。表 5-1 对 Scikit-learn 的 SVM 分类模型进行比较。