 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- zipkin操作指南
- 概念
- 页面介绍
- 详细介绍
- 更多操作
zipkin操作指南
概念
Span:基本工作单元,一次链路调用(可以是 RPC,DB 等没有特定的限制)创建一个 span,通过一个64位 ID 标识它,span 通过还有其他的数据,例如描述信息,时间戳,key-value 对的(Annotation) tag 信息,parent-id 等,其中 parent-id 可以表示 span 调用链路来源,通俗的理解 span 就是一次请求信息
Trace:类似于树结构的 Span 集合,表示一条调用链路,存在唯一标识
Annotation:注解,用来记录请求特定事件相关信息(例如时间),通常包含四个注解信息
cs - Client Start,表示客户端发起请求sr - Server Receive,表示服务端收到请求ss - Server Send,表示服务端完成处理,并将结果发送给客户端cr - Client Received,表示客户端获取到服务端返回信息
BinaryAnnotation:提供一些额外信息,一般已 key-value 对出现
页面介绍
上图是 zipkin 的筛选菜单,有以下几个过滤维度:
1,服务名
2,url
3,时间区间 start time - end time
4,Duration 只显示时长大于所填值的 trace
5,条数限制 只显示当前排序规则下前N条数据

点击Find Traces按钮,将依据指定的过滤规则,过滤出结果;使用Sort可以改变排序规则。有六种排序规则点击JSON按钮,可以切换图标形式和Json形式。
点击Find Traces按钮,列出了适合条件的trace标签。
详细介绍
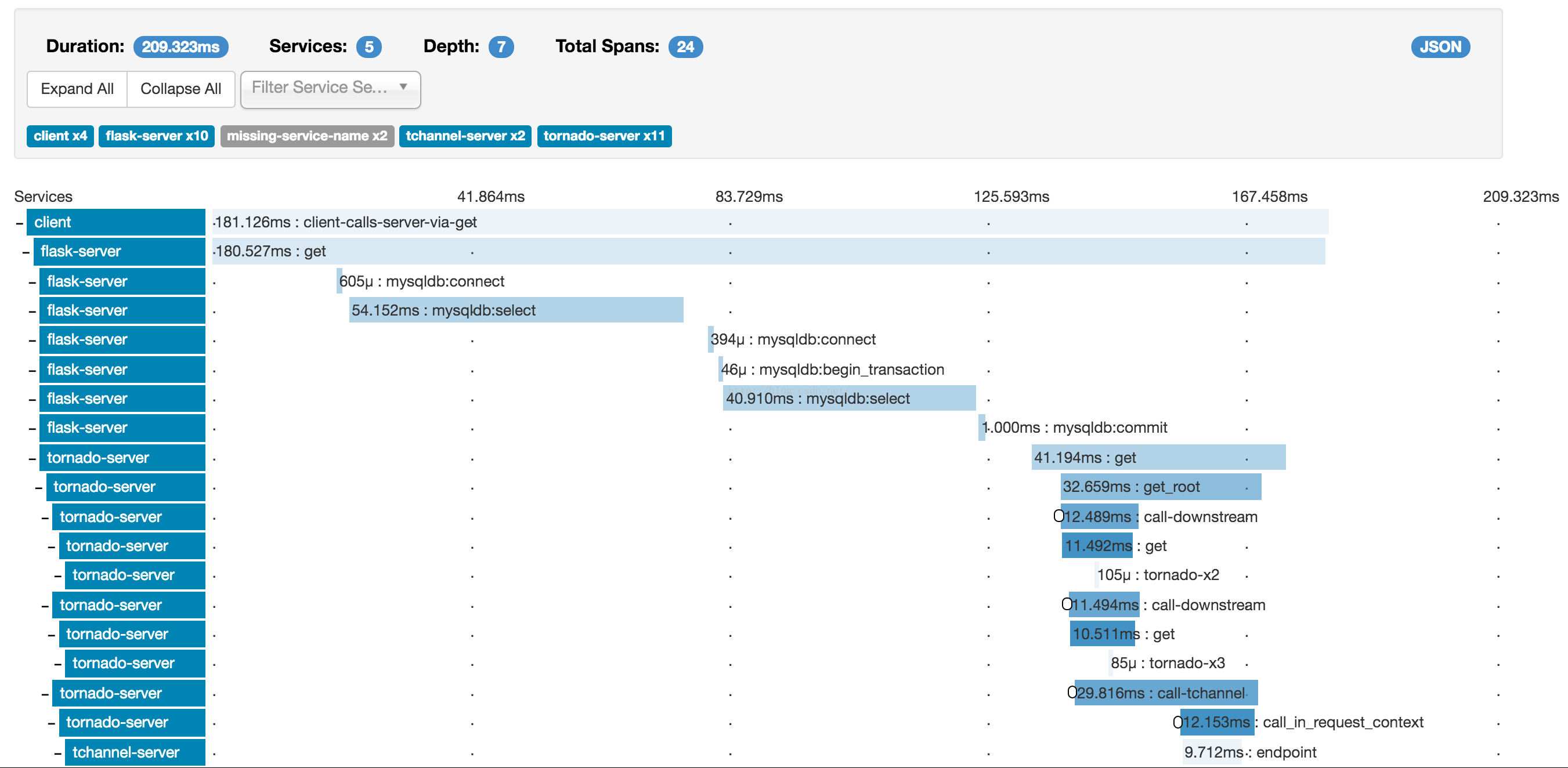
点击某一 trace,即可进入该 trace 的详细页面,可以看出调用链中的 span 顺序,每个 span 标注其所消耗的时间
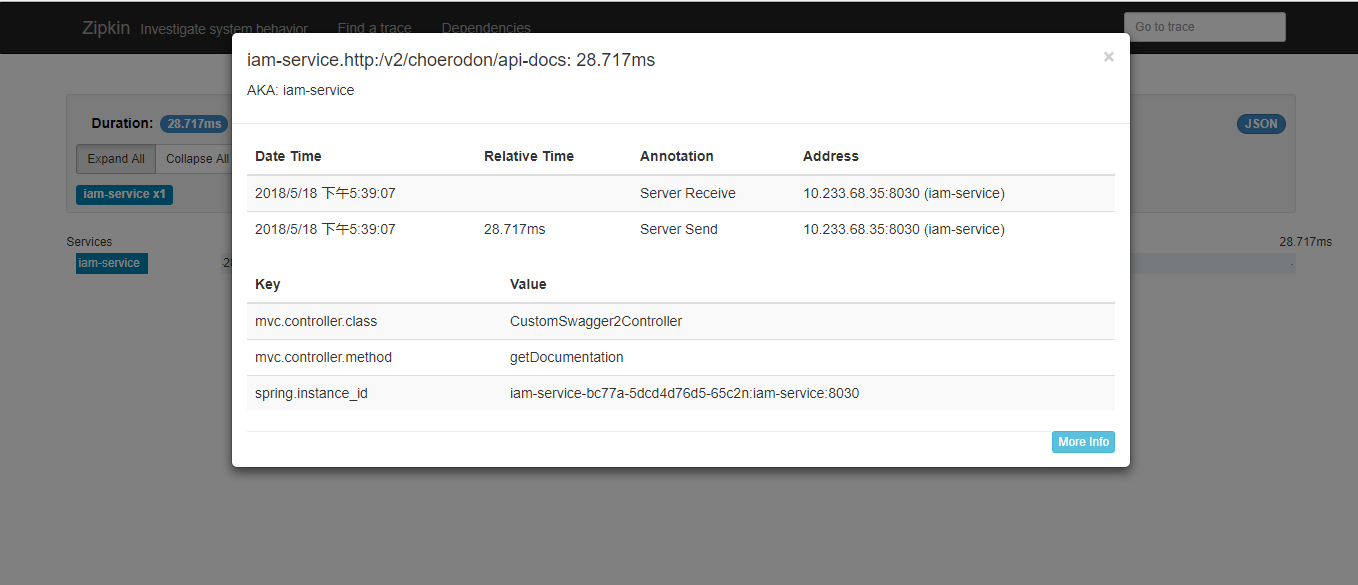
点击每个 span ,可以看出其详细的 API 调用顺序,通过对 sr , ss , cs , cr 时间的计算,可以得出每个调用的详细延迟,从而对调用链进行相应的分析。
更多操作
- Elasticsearch监控
- Kafka监控
- Kibana基础入门
- MySQL监控
