- 功能特性
- 1 支持多种深度学习框架
- 2 基于HDFS的统一数据管理
- 3 可视化界面
- 4 原生框架代码的兼容性
功能特性
1 支持多种深度学习框架
支持TensorFlow、MXNet分布式和单机模式,支持所有的单机模式的深度学习框架,如Caffe、Theano、PyTorch等。对于同一个深度学习框架支持多版本和自定义版本。
2 基于HDFS的统一数据管理
训练数据和模型结果统一采用HDFS进行存储,用户可通过—input-strategy或xlearning.input.strategy指定输入数据所采用的读取方式。目前,XLearning支持如下三种HDFS输入数据读取方式:
- Download: AM根据用户在提交脚本中所指定的输入数据参数,遍历对应HDFS路径下所有文件,以文件为单位将输入数据平均分配给不同Worker。在Worker中的执行程序对应进程启动之前,Worker会根据对应的文件分配信息将需要读取的HDFS文件下载到本地指定路径;
- Placeholder: 与Download模式不同,Worker不会直接下载HDFS文件到本地指定路径,而是将所分配的HDFS文件列表通过环境变量
INPUT_FILE_LIST传给Worker中的执行程序对应进程。执行程序从环境变量os.environ["INPUT_FILE_LIST"]中获取需要处理的文件列表,直接对HDFS文件进行读写等操作。该模式要求深度学习框架具备读取HDFS文件的功能,或借助第三方模块库如pydoop等。 InputFormat: XLearning集成有MapReduce中的InputFormat功能。在AM中,根据“split size”对所提交脚本中所指定的输入数据进行分片,并均匀的分配给不同Worker。在Worker中,根据所分配到的分片信息,以用户指定的InputFormat类读取数据分片,并通过管道将数据传递给Worker中的执行程序进程。
同输入数据读取类似,用户可通过—output-strategy或xlearning.output.strategy指定输出结果的保存方式。XLearning支持如下两种结果输出保存模式:Upload: 执行程序结束后,Worker根据提交脚本中输出数据参数,将本地输出路径保存文件上传至对应HDFS路径。为方便用户在训练过程中随时将本地输出上传至HDFS,XLearning系统在作业执行Web界面提供对输出模型的当前状态主动保存的功能,详情请见“可视化界面”说明部分;
- OutputFormat: XLearning集成有MapReduce中的OutputFormat功能。在训练过程中,Worker根据指定的OutputFormat类,将结果输出至HDFS。
更多详细说明见数据管理说明
3 可视化界面
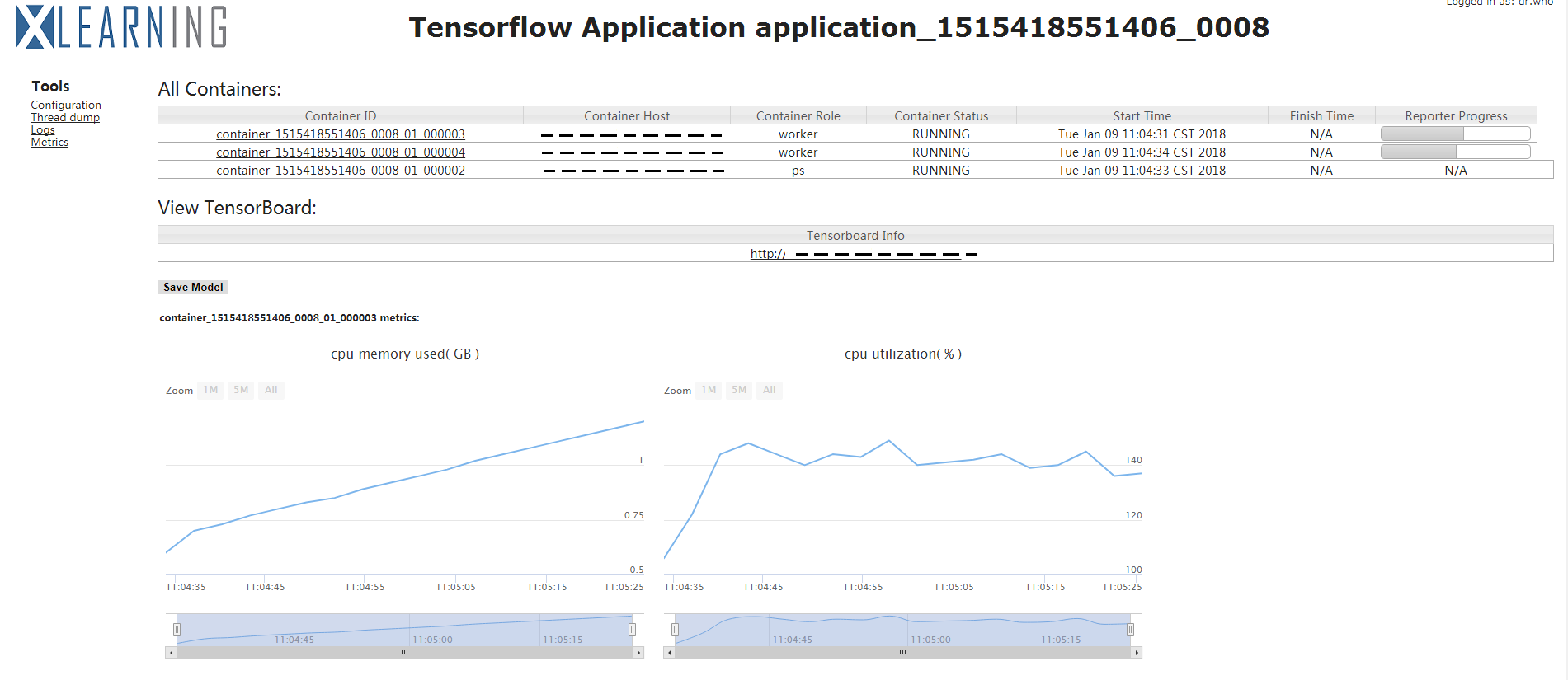
作业运行界面大致分为四部分:
- All Containers:显示当前作业所含Container列表及各Container对应信息,如Contianer ID、所在机器(Container Host)、所属类型(Container Role)、当前执行状态(Container Status)、开始时间(Start Time)、结束时间(Finish Time)、执行进度(Reporter Progress)。其中,点击Container ID超链接可查看该Container运行的详细日志;
- View TensorBoard:当作业类型为TensorFlow时,可点击该链接直接跳转到TensorBoard页面;
- Save Model:当作业提交脚本中“—output”参数不为空时,用户可通过
Save Model按钮,在作业执行过程中,将本地输出当前模型训练结果上传至HDFS。上传成功后,显示目前已上传的模型列表; - Worker Metrix:显示各worker执行所占用的资源信息。
如下图所示:
4 原生框架代码的兼容性
TensorFlow分布式模式支持“ClusterSpec”自动分配构建,单机模式和其他深度学习框架代码不用做任何修改即可迁移到XLearning上。
